There's a post on the fetch() API by Ludovico Fischer doing the rounds. As a co-instigator for adding the API to the platform, it's always a curious thing to read commentary about an API you designed, but this one more than most. It brings together the epic slog that was the Promises design (which we also waded into in order to get Service Workers done and which will improve with await/async) with the in-process improvements that will come from Streams and it mixes it with a dollop of FUD, misunderstanding, and derision.
This sort of article is emblematic of a common misunderstanding. It expresses (at the end) a latent belief that there is some better alternative available for making progress on the web platform than to work feature-by-feature, compromise-by-compromise towards a better world. That because the first version of fetch() didn't have everything we want, it won't ever. That there was either some other way to get fetch() shipped or that there was a way to get cancellation through TC39 in '13. Or that subclassing is somehow illegitimate and "non-standard" (even though the subclass would clearly be part of the Fetch Standard).
These sorts of undirected, context-free critiques rely on snapshots of the current situation (particularly deficiencies thereof) to argue implicitly that someone must be to blame for the current situation not yet being as good as the future we imagine. To get there, one must apply skepticism about all future progress; "who knows when that'll be done!" or "yeah, fine, you shipped it but it isn't available in Browser X!!!".
They're hard to refute because they're both true and wrong. It's the prepper/end-of-the-world mentality applied to technological progress. Sure, the world could come to a grinding halt, society could disintegrate, and the things we're currently working on could never materialize. But, realistically, is that likely? The worst-case-scenario peddlers don't need to bother with that question. It's cheap and easy to "teach the controversy". The appearance of drama is its own reward.
Perhaps most infuriatingly, these sorts of cheap snapshots laced with FUD do real harm to the process of progress. They make it harder for the better things to actually appear because "controversy" can frequently become a self fulfilling prophesy; browser makers get cold feet for stupid reasons which can create negative feedback loops of indecision and foot-gazing. It won't prevent progress forever, but it sure can slow it down.
I'm disappointed in SitePoint for publishing the last few paragraphs in an otherwise brilliant article, but the good news is that it (probably) won't slow Cancellation or Streams down. They are composable additions to fetch() and Promises. We didn't block the initial versions on them because they are straightforward to add later and getting the first versions done required cuts. Both APIs were designed with extensions in mind, and the controversies are small. Being tactical is how we make progress happen, even if it isn't all at once. Those of us engaged in this struggle for progress are going to keep at it, one feature (and compromise) at a time.
It happens on the web from time to time that powerful technologies come to exist without the benefit of marketing departments or slick packaging. They linger and grow at the peripheries, becoming old-hat to a tiny group while remaining nearly invisible to everyone else. Until someone names them.
This may be the inevitable consequence of a standards-based process and unsynchronized browser releases. We couldn't keep a new feature secret if we wanted to, but that doesn't mean anyone will hear about it. XMLHTTPRequest was available broadly since IE 5 and in Gecko-based browsers from as early as 2000. "AJAX" happened 5 years later.
This eventual adding-up of new technologies changes how we build and deliver experiences. They succeed when bringing new capabilities while maintaining shared principles:
URLs and links as the core organizing system: if you can't link to it, it isn't part of the web
Markup and styling for accessibility, both to humans and search engines
UI Richness and system capabilities provided as additions to a functional core
Free to implement without permission or payment, which in practice means standards-based
Major evolutions of the web must be compatible with it culturally as well as technically.
Many platforms have attempted to make it possible to gain access to "exotic" capabilities while still allowing developers to build with the client-side technology of the web. In doing so they usually jettison one or more aspect of the shared value system. They aren't bad — many are technically brilliant — but they aren't of the web:
These are just the ones that spring to mind offhand. I'm sure there have been others; it's a popular idea. They frequently give up linkability in return for "appiness": to work offline, be on the home screen, access system APIs, and re-engage users they have required apps be packaged, distributed through stores, and downloaded entirely before being experienced.
Instead of clicking a link to access the content you're looking for, these systems make stores the mediators of applications which in turn mediate and facilitate discovery for content. The hybridzation process generates applications which can no longer live in or with the assumptions of the web. How does one deploy to all of these stores all at once? Can one still keep a fast iteration pace? How does the need to package everything up-front change your assumptions and infrastructure? How does search indexing work? It's a deep tradeoff that pits fast-iteration and linkability against offline and store discovery.
Escaping the Tab: Progressive, Not Hybrid
But there is now another way. An evolution has taken place in browsers.
Over dinner last night, Frances and I enumerated the attributes of this new class of applications:
Linkable: meaning they're zero-friction, zero-install, and easy to share. The social power of URLsmatters.
These apps aren't packaged and deployed through stores, they're just websites that took all the right vitamins. They keep the web's ask-when-you-need-it permission model and add in new capabilities like being top-level in your task switcher, on your home screen, and in your notification tray. Users don't have to make a heavyweight choice up-front and don't implicitly sign up for something dangerous just by clicking on a link. Sites that want to send you notifications or be on your home screen have to earn that right over time as you use them more and more. They progressively become "apps".
Critically, these apps can deliver an even better user experience than traditional web apps. Because it's also possible to build this performance in as progressive enhancement, the tangible improvements make it worth building this way regardless of "appy" intent.
Frances called them "Progressive Open Web Apps" and we both came around to just "Progressive Apps". They existed before, but now they have a name.
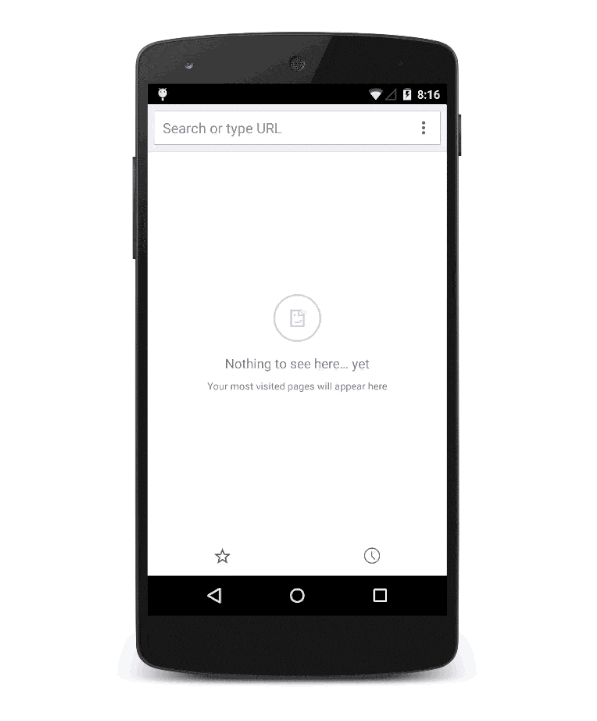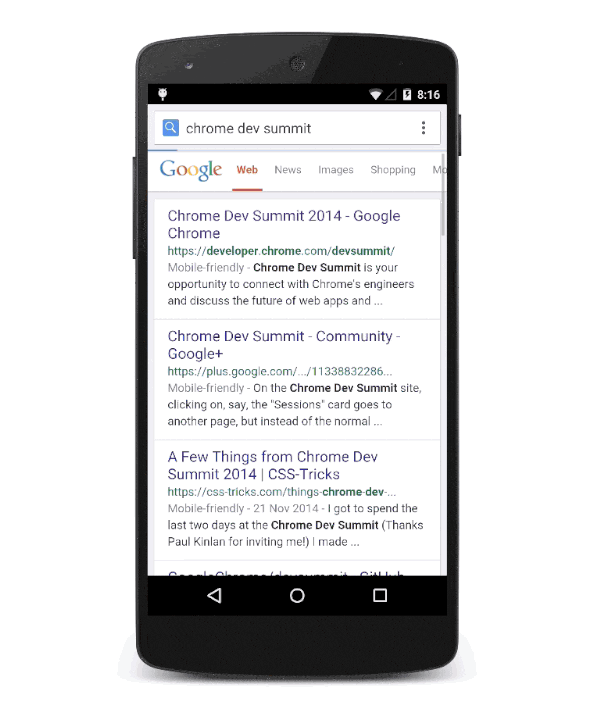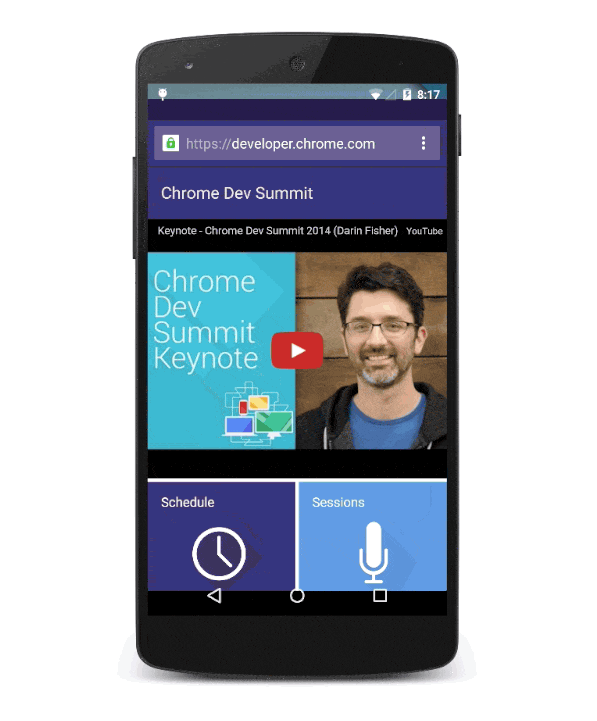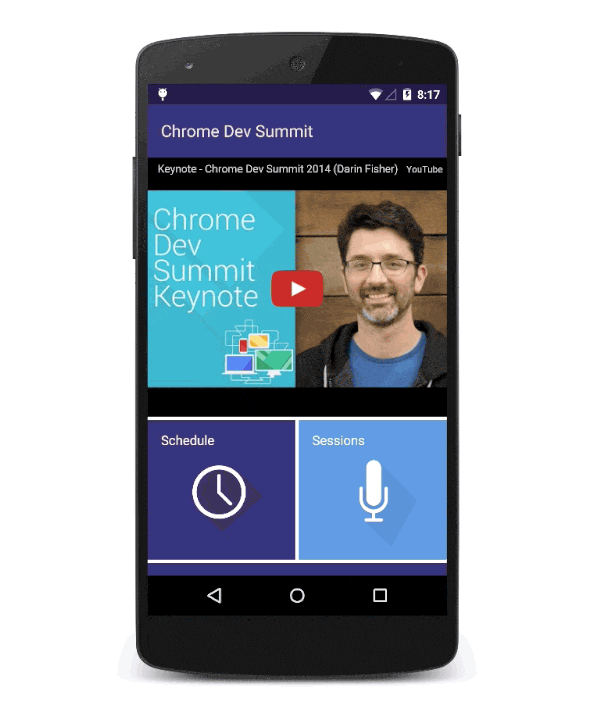
The site begins life as a regular tab. It doesn't have super-powers, but it is built using Progressive App features including TLS, Service Workers, Manifests, and Responsive Design.
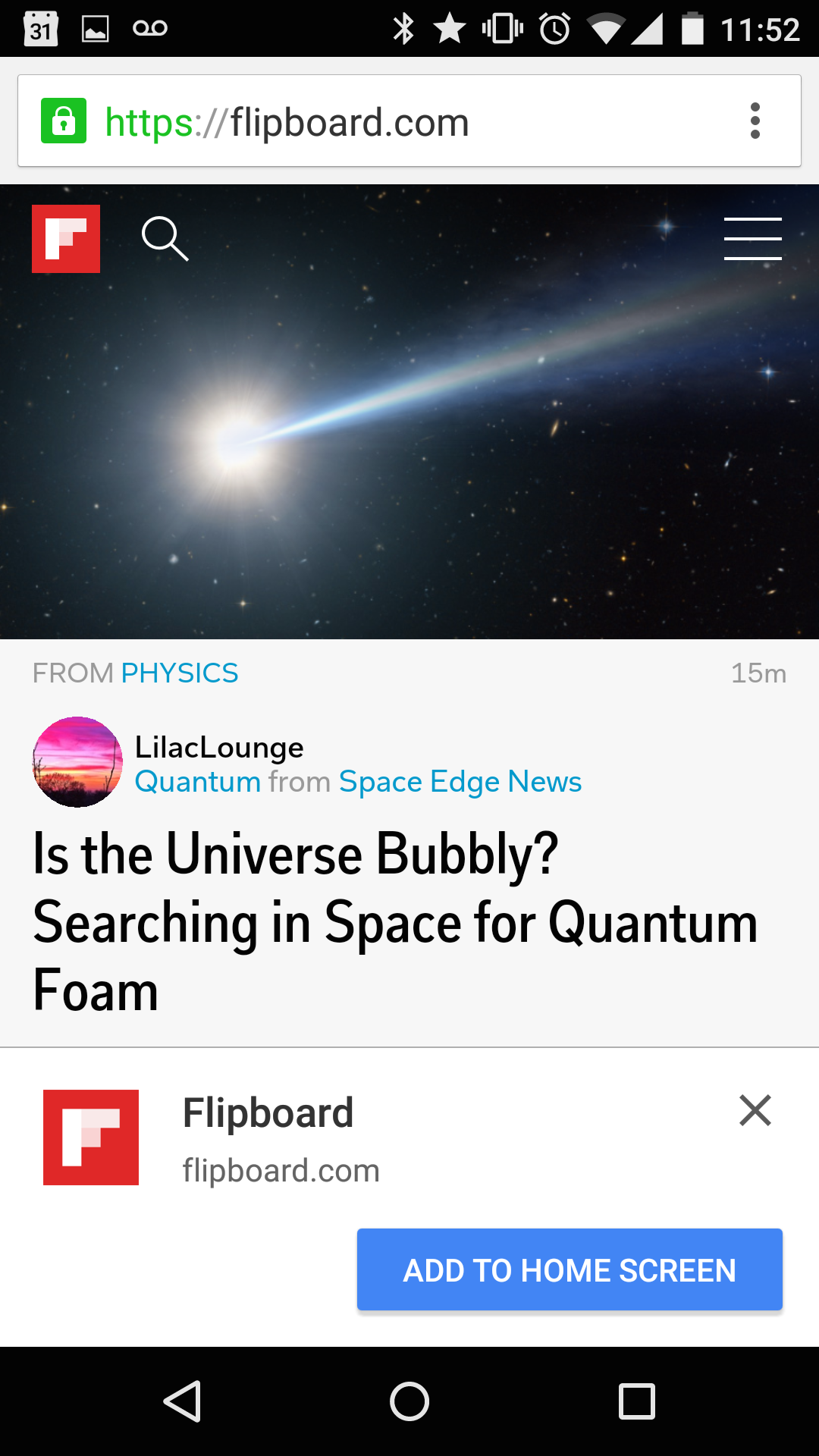
The second (or third or fourth) time one visits the site -- roughly at the point where the browser it sure it's something you use frequently -- a prompt is shown by the browser (populated from the Manifest details)
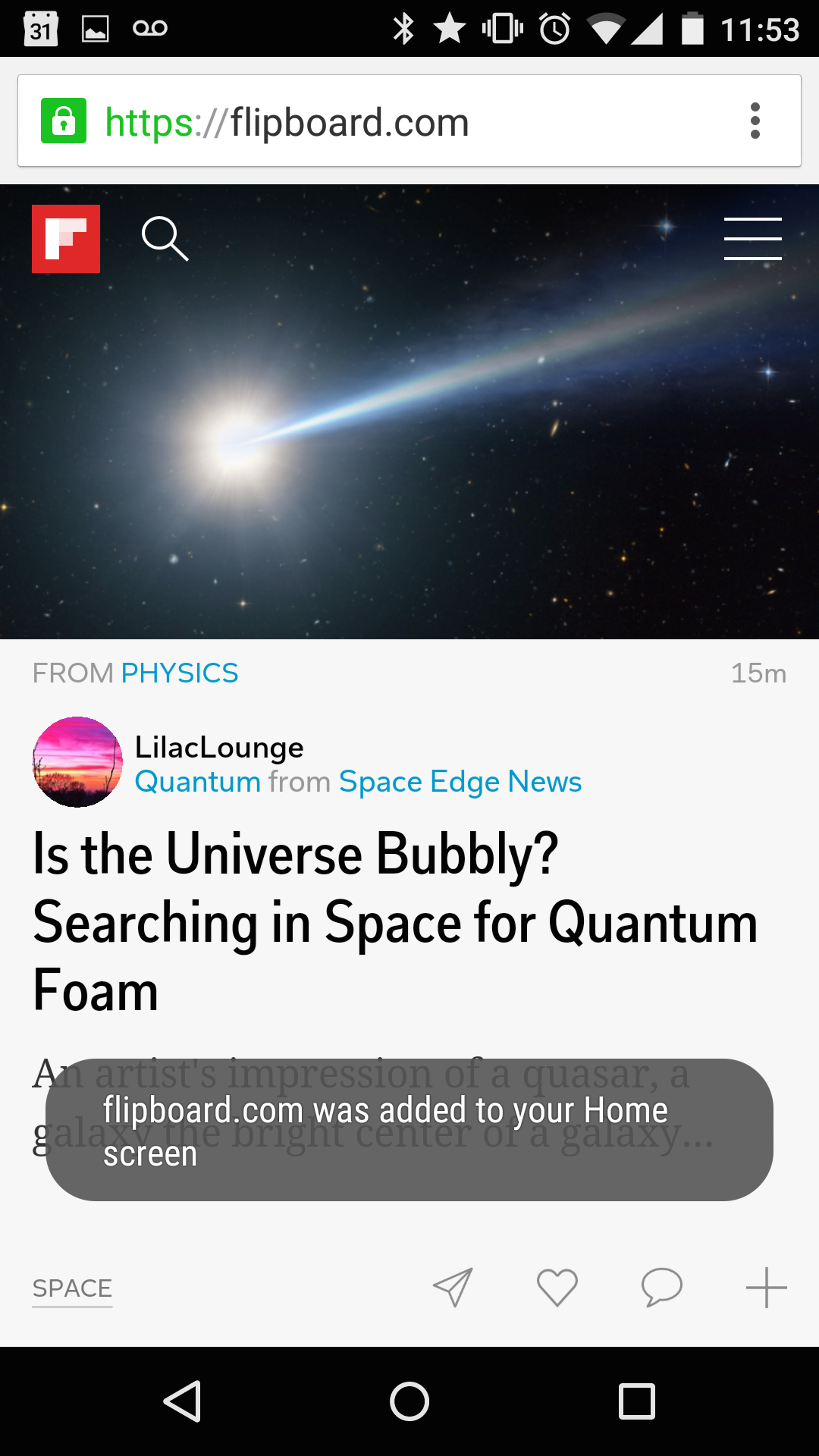
Users can decide to keep apps to the home screen or app launcher
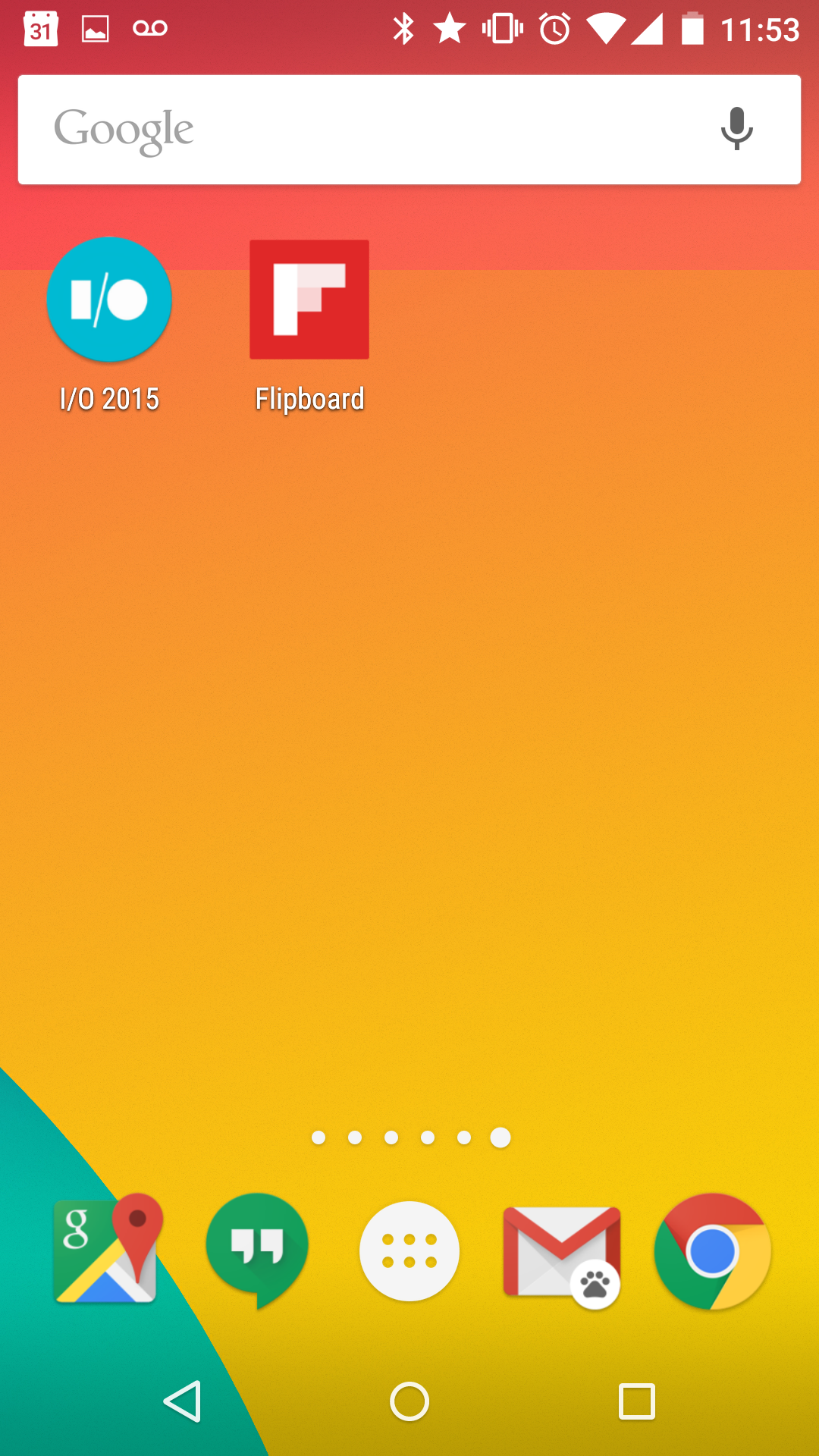
When launched from the home screen, these apps blend into their environment; they're top-level, full-screen, and work offline. Of course, they worked offline after step 1, but now the implicit contract of "appyness" makes that clear.
Progressive Web App installation flow for Chrome Dev Summit.
Here's the same flow on Flipboard today:
Progressive Apps are web apps, they begin life in a tab. Here we see flipboard.com in Chrome for Android with regular tab treatment.When users engage with Progressive Web Apps enough, browsers offer prompts that ask users if they want to keep them. To avoid spaminess, this doesn't happen on the first load.If the user accepts, the user's flow isn't interrupted.The app shortcut appears on the homescreen or launcher of the OS.When launched, Progressive Web Apps can choose to be full-screen.Progressive Web Apps are top-level activities in the OS's application switcher.
The Future
Today's web development tools and practices don't yet naturally support Progressive Apps, although many frameworks and services are close enough to be usable for making Progressive Apps. In particular, client-side frameworks that have server-rendering as an option work well with the model of second-load client-side routing that Progressive Apps naturally adopt as a consequence of implementing robust offline experiences.
This is an area where thoughtful application design and construction will give early movers a major advantage. Full Progressive App support will distinguish engaging, immersive experiences on the web from the "legacy web". Progressive App design offers us a way to build better experiences across devices and contexts within a single codebase but it's going to require a deep shift in our understanding and tools.
Building immersive apps using web technology no longer requires giving up the web itself. Progressive Apps are our ticket out of the tab, if only we reach for it.
IF YOU DO NOT RUN A SITE THAT HOSTS UNTRUSTED/USER-PROVIDED FILES OVER SSL/TLS, YOU CAN STOP READING NOW
This post describes the potential amplification of existing risks that Service Workers bring for multi-user origins where the origin may not fully trust the content or, in which, users should not be able to modify each other's content.
Sites hosting multiple-user content in separate directories, e.g. /~alice/index.html and /~bob/index.html, are not exposed to new risks by Service Workers. See below for details.
Sites which host content from many users on the same origin at the same level of path separation (e.g. https://example.com/alice.html and https://example.com/bob.html) may need to take precaution to disable Service Workers. These sites already rely on extraordinary cooperation between actors and are likely to find their security assumptions astonished by future changes to browsers.
Like AppCache, Service Workers are available without user prompts and enable developers to create meaningful offline experiences for web sites. They are, however, strictly more powerful than AppCache.
To mitigate the risks associated with request interception, Service Workers are only available to use under the following restrictions:
Service Workers are restricted to secure origins. E.g., http://acme.com/ can never have a Service Worker installed, whereas https://acme.com can. If you do not serve over SSL/TLS, service workers do not impact your site.
Service Worker scripts must be hosted at the same origin. E.g., https://acme.com/index.html can only register a Service Worker script if that script is also hosted at https://acme.com. Scripts included by the root Service Worker via importScripts() may come from other origins, but the root script itself cannot be registered against another origin. Redirects are also treated as errors for the purposes of SW script fetching to ensure that attackers cannot turn transient ownership into long-term control.
Service Workers are restricted by the path of the Service Worker script unless the Service-Worker-Scope: ... header is set.
Service Workers intercept requests for documents and their sub-resources. These documents are married to SW's based on longest-prefix-match of the path component of the script which is registered with the scopes.
For example, if https://acme.com/thinger/index.com registers a SW hosted at https://acme.com/thinger/sw.js, it cannot by default intercept requests for https://acme.com/index.html
This example may, however, respond for more-specific document requests like https://acme.com/thinger/blargity/index.html.
If the script is instead located at https://acme.com/sw.js, the registration will allow interception for all navigations at https://acme.com/.
This means that sites hosting multiple-user content in separated directories, e.g. /~alice/ and /~bob/, are not exposed to new risks by Service Workers.
Sites which host multiple user's content in the same directories may wish to consider disabling Service Workers (see below).
Servers can break this restriction on allowed scope by sending a Service-Worker-Scope: ... header, where the value of the header is the allowed path (e.g., /). This feature will not arrive for Chrome until version 41 (6 weeks after the original release which adds support for Service Workers).
Service Worker scripts must be served with valid JavaScript mime types, e.g. text/javascript. Resources served with marginal Content-Type values, e.g. text/plain, will NOT be respected as valid Service Worker scripts.
If you run a site which hosts untrusted third-party content on a single origin over SSL/TLS, you should ensure that you:
Disable Service Workers at your origin by blocking requests which include the Service-Worker: script header. This is easily accomplished using global server configuration (e.g. httpd.conf directives).
If you wish to allow Service Workers, Begin auditing use of Service Workers on your origin as requests which include Service-Worker: script may indicate other problems with content hosting (e.g., if you do not mean to be hosting active HTML content but are doing so incidentally).
Move to a sub-domain-per-user model as soon as possible, e.g. https://alice.example.com instead of https://example.com/~alice. The browser-enforced same-origin model is fundamentally incompatible with serving content from multiple entities at the same origin. For instance, sites which can run on the same origin are susceptible to easy-to-make mixups with Cookie paths and storage poisoning attacks via Local Storage, WebSQL, IndexedDB, the Filesystem API, etc. The browser's model for how to separate principals relies almost exclusively on origins and we strongly recommend that you separate users by sub-domain (which is a different origin) so that future changes to browsers do not cause harmful interactions with your hosting setup.
Jeremy Keith is wringing his hands about Web Components. I likewise can't attend the second Extensible Web Summit and so have a bit of time to respond here.
Full disclosure: I helped design Web Components and, with Dimitri Glazkov and Alex Komoroske, helped lead the team at Google that brought them from concept to reality. I am, as they say, invested.
Jeremy's argument, if I can paraphrase, is that people will build Web Components and this might be bad. He says:
Web developers could ensure that their Web Components are accessible, using appropriate ARIA properties.
But I fear that Sturgeon’s Law is going to dominate Web Components. The comparison that’s often cited for Web Components is the creation of jQuery plug-ins. And let’s face it, 90% of jQuery plug-ins are crap.
Piffle and tosh.
90% of JQuery plugins don't account for 90% of the use of JQuery plugins. The distribution of popularity is as top-heavy there as it is in the rest of the JS UI library landscape in which developers have agency to choose components on quality/price/etc. The implicit argument seems willfully ignorant of the recent history of JS libraries wherein successful libraries receive investment and scrutiny, raising their quality level. Indeed, the JS library world is a towering example of investment creating better results: the winners are near-universally compatible with progressive enhancement, a11y, and i18n. If there's any lesson to be learned it should be that time and money can improve outcomes when focused on important libraries. Doing general good, then, comes down to aiming specific critique and investment at specific code. A corollary is that identifying which bits will have the most influence in raising the average is valuable.
Web Components do this cycle a solid: because they are declarative by default we don't need to rely on long-delayed developer surveys to understand what is in wide use. Crawlers and browsers that encounter custom elements can help inform our community about what's most popular. This will allow better and more timely targeting of investment and scrutiny.
This is worlds different than browser feature development where what's done is done and can scarcely change.
A particularly poor analogy is deployed in the argument that Web Components are somehow a rehash of Apple's introduction of <meta name="viewport" value="...">. This invokes magical behavior in some browsers. We're meant to believe that this is a cautionary tale for an ecosystem of intentionally included component definitions which cannot introduce magic and which are not bound by a closed vocabulary that is defacto exclusive and competitive -- other browsers couldn't easily support the same incantation and provide different behavior without incurring developer wrath. The difference in power and incentives for browser vendors and library authors ought to make the reader squirm, but the details of the argument render it entirely limp. There is no reasonable comparison to be drawn.
This isn't to ignore the punchline, which is that copy/paste is a powerful way of propagating (potentially maladaptive) snippets of content through the web. Initial quality of exemplars does matter, but as discussed previously, ignoring the effects that compound over time leads to a poor analysis.
Luckily we've been thinking very hard about this at Google and have invested heavily in Polymer and high-quality Material Design components that are, as I write this, undergoing review and enhancement for accessibility. One hopes this will ease Jeremy's troubled mind. Seeding the world with a high-quality, opinionated framework is something that's not only happening, it's something we've spent years on in an effort to provide one set of exemplars that others can be judged against.
Overall, the concerns expressed in the piece are vague, but they ought not be. The economics of the new situation that Web Components introduce are (intentionally) tilted in a direction that provides ability for cream to rise to the top -- and for the community to quickly judge if it smells off and do something about it.
Yes, messes will be made. But that's also the status quo. We get by. The ecosystem sets the incentives and individuals can adapt or not; the outcomes are predictable. What matters from here is that we take the opportunity to apply Jeremy's finely-tuned sense of taste and focus it on specific outcomes, not the entire distribution of possible outcomes. It's the only way to make progress real.
PS: Extensibility and the Manifesto aren't about about Web Components per sae. Yes, we extracted these principals from the approach our team took towards building Web Components and the associated technologies, but it cuts much, much deeper. It's about asking "how do these bits join up?" when you see related imperative and declarative forms in the platform. When there's only declarative and not imperative, extensibility begs the question "how does that thing work? how would we implement it from user-space?". Web Components do this for HTML. Service Workers do this for network caching and AppCache. Web Audio is starting to embody this for playing sound in the platform. There's much more to do in nearly every area. We must demand the whole shebang be explained in JS or low-level APIs (yes, I AM looking at you, CSS).
Something irks me about the phrase "semantic HTML".
The intent is clear enough -- using HTML in ways that are readable, using plain language to describe things. But that's not what "semantic" means. We might as well be saying "well written" or "copy edited". They'd be closer fits. What we describe today as "unsemantic markup" isn't really; there is actual meaning to end-users, but it is conveyed with long-winded markup. Bloviating, but not "unsemantic".
Convoluted and hard to grok -- like my writing -- is bad. Simple and direct is good. Defining what "simple" and "direct" are is hard as it involves questions of meaning and what authors (webdevs) can assume of readers (browsers). We have phrases for that: e.g. "an 8th grade reading level". The presumption of sophisticated readers makes terseness and subtlety possible. It also is what makes great works so difficult to translate. Defining terms isn't required among the proficient. There's real value in improving the overall literacy of an ecosystem.
Using "semantic" in a way that talks about simplicity and the underlying meaning indicates a deep confusion about how language works, the role of developers in getting it across, and the real-world potential of the web to carry more meaning over time. Why is this important? And isn't "semantic HTML" good?
Perhaps. I tend to think it depends on how much you ascribe the rise of the web as a platform to luck and how much you attribute to its particular attributes; my guess is ~40/60 luck+timing vs. attributes. There's no experimental evidence for that weighting beyond observing the relative successes of Flex, XAML, OpenLaszlo, JavaFX, and Android layouts versus both each other and their more imperative competitors. It's difficult to design or run experiments about UI framework adoption.
Regardless, we can sketch out a working model of the actors, their interests, and what they derive from HTML to help explain the value created in that ~60%. Doing this will give us a sense for what HTML's semantics really are, how they came to be, and what it would mean to meaningfully evolve them. With a model in mind we can examine how changes to HTML impact its diverse consumers. It also gives us a way to anticipate the impact of JavaScript and extensions to HTML (microformats, RDFa, and Schema.org). Much hope and fear have been located in them, but we can move past pure speculation and discuss mechanisms when we have a working model that we can mark to observable reality.
Such a model can be constructed several ways but I think it's most effective to look at HTML's largest constituencies and uncover what they want and get from HTML, CSS, and JS. From there, we can chart the intersections of those interests and discuss how value is created and transferred.
The Constituencies
Developers
High-level systems like HTML deliver huge value by providing the ability to manipulate -- and be insulated from -- many nasty layers of software. Even in the midst of a quest to explain the layers of the web platform in terms of lower-level things we must not forget the value high-level, largely-declarative forms deliver.
Giving developers (indirect) power over those layers of software from an easy-to-modify-and-iterate format, and doing it in a way that enables folks who wouldn't even think of themselves as "developers" to do the same creates monumental power. VB-style power: the sort that makes the smart-but-technologically-stranded finally self-sufficient. Ctrl-R as "make all" for the web isn't perfect, but it is hugely enabling. The modern devtools revolution even more-so. The impact of directness can't be overstated. Cue Bret Victor: "creators need an immediate connection".. Declarative forms pay off big when they meet user needs.
HTML makes heroes out of mortals. Like some sort of cheesy comic book origin story, the directness and forgiveness of HTML give "non developers" the ability to make things which they can then give to other people. Things those people want. This is what tools do when they're good. And sneakily it sort of doesn't look like code.
The first-person value of HTML to developers is all about putting things on screens to look at and interact with. There's some weird strain of the "linked data" and "semantic HTML" zeitgeist that forgets this. The primary reason people build things on the web is because they want some other human to find and have their lives enriched by that thing. Most of the time that's about visual and interactive value: showing, putting-in-context, displaying.
It's a conversation between the developer and users. One in which the developer wields often-inadequate tools to communicate something; most often visually. What everyone else (search engines, publishers, etc.) get out of this arrangement is as side effect; an echo of the original conversation.
Developers are attempting to re-create in the minds of users what they had in mind for them to understand. What's important in an article. What's navigation vs. main-body content. What bits of the form are really required. Nothing about this process is technical from the perspective of the user. The semantic content is what end users perceive.
Let that really sink in. PowerPoint slides or PDF forms can transmit nearly all the same semantics as HTML from the perspective of users -- the visual and interactive content that is perceived to be the "meaning" of the content most of the time.
I submit that HTML has succeeded because it turned people who didn't know anything about programming into great communicators. They could suddenly cause forms, and checkboxes, and paragraphs, and images to be.
Think on the humble <a href="...">: it comes with UI to distinguish links from regular text (underlining) plus conventions and system support for location (visited, hover, etc.), and the ability to respond to input (navigating on click). The code to do all of this would be daunting, and you'd never get everyone bought off on the same conventions unless the system provided some. But the anchor tag provided it all: relationships between text and locations, built-in UI, behavioral support, and most of all an incredibly terse package that made all of that power accessible to anyone with a text editor and an FTP client.
Lest you be tempted to ignore the value of the visual and interactive conventions, consider a world without them. Or a world where the browser had JS APIs for navigating to new documents, but no built-in system for synthesizing clicks into navigations. Sure, spontaneous order could arise, but probably not. There's no standard way to "link" between Flash content and it has had nearly as long. It's safe to say that providing affordances to users to help them do things they want to do is why HTML has been a success.
Those affordances, from the perspective of users, are the semantic conventions of the web. They are the building blocks of a visual and interactive language. They are the content and the meaning.
End Users
Technology is largely a chore for end-users. It forms a superstructure for things that actually matter -- family, love, acceptance, work -- it enables and hinders, often at the same time.
Technology, the web, "apps"...these are middlemen. Good middlemen make it easy to get what we want and will get the repeat business. The job of good technology is to help end users get what they want faster, more easily, and with less hassle. Therefore it does not pay to have unique UI unless you wish to express something very valuable that the existing system can't. The stifling communitarian apects of visual and interactive conventions isn't a fluke. Users, designers, and platforms all co-evolve our visual language. Straying too far from the flock gets your app eaten.
HTML's economics favor built-in UI components over per-page components; it's faster and easier even if the UX isn't perfect for the local site. Users understand them and so does the system which provides default UI for "free" (sites don't have to build/send it in JS). This increases the relative price of wheel re-invention via JavaScript.
The biggest revolution of the web is the search engine. Built on the back of HTML's conventions, search engines make it possible not only for anyone to publish but for most to find. PageRank famously exploited the web's conventions to extract meaning from chaos. Search crawlers can "see" the same content that users do (it's not hidden in binary code, only unveiled at runtime) so it's possible to provide value to users in a whole new way.
UI conventions with economic superiority and inter-document relationships have created an industry and have given most of the folks reading this treatise jobs. Behold the power of default UI.
Not all users are the same, of course. For many, the default UI is meaningless or close to it. HTML shines for them too, not because it made everyone care about accessibility but because it once again allowed second-party tools, agents of users, to re-interpret high-level intent in a different low-level context: reading instead of blitting, e.g.
Once again, the incredible power of defaults plays a supporting role: no assistive technology would have had a shot if the built-in library of elements wasn't usually used mostly in the same ways. Same story with web crawlers. The incentives that weigh on web developers are the only thing that keep the <a> from long-since having been re-styled to be a block container by default (why not? it's shorter to type than <div>). Those incentives derive from wanting to communicate to most end users (the ones who don't use assistive technologies). The easiest and best way to do that is to avoid re-defining words. Let the browser do the work of rendering UI, stick with the rest of the pack and use words in the normal way, and don't try to introduce too much new vocabulary unless it's absolutely necessary.
These reinforcing dynamics drive prices down and value up. Using HTML that all browsers understand saves on complexity, latency, and confusion -- assuming that HTML has something that says what you mean. The benefits are enormous at the macro scale, but they derive predictably from costs and incentives that start at the micro scale: developers trying to communicate things to users, nevermind anyone else.
And one last thing...I can't leave URLs out of the end-user value proposition. No system before or since has been as good at making things available to be shared as the proliferation of URLs for addressing content. They are the proto-social backbone of the web. For users, being able to copy/paste links creates a world of opportunity to do things app authors don't have to pre-arrange support for. Once again, browser-provided default behavior bootstraps massive benefits.
Publishers
Markup, the plain-text web, and the ability to enable searchability has been a mixed business bag for publishers, of course. But as a consumer of this stuff, it has been ace. Lets say a publisher wants to publish electronically...what's in the web for them?
URLs and searchability. If links and shareability are good for users, they're killer for publishers. Social behavior pays them back most directly, and URLs are the grease in those gears. Without having to build a second or 3rd version, the web made "building a website" also enable linkability for very little extra work. Indeed, in most modern frameworks you have to try hard not to end up with decent URLs.
The de-facto searchability of HTML allows publishers to leverage their investment in end-user publishing infrastructure again. No re-building another version. No one-off data interchange formats. Configuration? Yes. Supersetting and side-contracts to improve information density? You bet. But no more wholesale re-writing.
Search Engines
The role of crawlers and engines is misunderstood by most everyone I talk to. Webdevs spend a lot of time thinking about "semantics" and "SEO" without any real conception of the goals and motives behind search pipeline. There are deep questions here -- what should a search engine return when I ask it a question? what is my relationship to it? -- but we can ignore them for now. My view is that the best answer a search engine can give you is the one you would have picked for yourself had you been able to read a corpus of billions of documents. And the explicit goal of the crawl engineers I have talked to is make that dream come true.
As a practical matter, what does that mean for semantics? Well, you wouldn't pick a document that hid half the content from you, would you? And you surely wouldn't have picked it for that content. Indeed, documents that present a different view to the crawler than to users are likely spammy. Looking at what Matt Cutts presents, you get a pretty clear picture: the index is trying to see the web the way you see it...and of course, then help you pick an answer. But that's all predicated on some sort of "understanding"...and the platonic ideal of "understanding" content isn't something to do with sub rosa embedded data, it's about the thing the page was trying to communicate to the user in the first place in the way the user would have understood it.
I can't stress this enough: when we as web developers get tied in knots about "semantics" and web crawlers, we're mostly worrying about absolutely the wrong thing. Sure, go figure out what works and what not to do, but the thing to always keep in the back of your mind is that all of this is temporary. The goal of search engines it to understand pages the way you do. To the extent they don't, that's a bug to be fixed -- and it will be.
If the goal of a search engine is to understand the page the way the user does, then the semantics we care about are the ones that are meaningful to users. The idea that we should create some other layer of meaning above/below/to-the-side of content is...a non-sequiter.
Consider tables.
You've likely been told all of your professional career that using <table> for things that aren't tabular data is EVIL (or at least "wrong"). Yet you also observe that many of the world's computers have not caught fire due to the misapplication of <table>. Or <li>. Or <dt>/<dd>.
On the one hand, yes, tables do help you visually format things in a tabular way. But the history of the web's layout-system hi-jinx led to a situation where the only compatible way to get full constraint programming power was to use tables for non-tabular data...as a layout container. This had some practical problems: some browsers were bad/slow at it. Incremental layout wasn't "a thing" yet. There were bugs. All of this served to stretch the canonical use of <table> well beyond tabular data. Without a common meaning through use, the UI value was diluted. Whatever lingering hope HTML purists have harbored for a world in which putting data in a <table> element suddenly makes it machine extractable is certainly far from today's state of the art; for 3 reasons:
Having tabular data in a table doesn't make it useful to anyone else. The <a> element at least gives users some way to use the relationship between the UI and the things it references beyond "pure presentation".
Nothing else in HTML knows how to consume that data. Even if you put all of your tabular data in a <table>, it doesn't make any other bit of your UI more powerful.
People lie
Forget machine extraction; <table> isn't a semantics failure because "people used it wrong", it never turned into a "semantic" thing because it never evolved far enough to have meaningful relationships with others; either users or other bits of the system.
But this analysis also charts a path forward: you know what sort of machine-readable extractable data source would be interesting to search engines? The sort that makes it easy for lots of people to refer to the same data. The sort that can provide users something to do with that data inside the document (by default). The fix wouldn't even be that huge, methinks.
Oh, and I did mention the lying, right?
Yes, people lie. And they hire machines to lie for them. Such is life. HTML can be "semantic" inside the constraints of its pre-defined vocabulary only to the extent that we all agree to use certain words the same way -- something we do more often when UI guides us: see the train wrecks that are HTML5 <article>, <section>, etc. People of good cheer acting in socially positive ways most of the time doesn't make all content any more trustable or authoritative, but it does raise the average. Our mental model about web semantics needs to assume that, out here on the big-bad internet, some bit of code that says that it's a something-or-other might be trying to deceive the user somehow. So quality metrics are the first stab at classification on the open web.
Do not be drawn in by the productive noises emanating from the academic linked-data community: they do not swim in the same soup.
Generally speaking, the academic solution to data quality is to pre-suppose a closed world in which only high-quality data is allowed in. This might be a reasonable place to start in terms of investigating what to do next, but it leaves those considering the solutions entirely unequipped to recon with the web as we have it. Identifying high-quality data isn't simple. Real-world systems always have to deal with "noise", either now or in the future via semantic drift (see below), so while one could focus on systems that deal in high-quality, low-noise corpuses of pre-classified data, that world isn't the web. It won't be. It can't be. The fact of liars, semantic drift, and the practical effects of Postel's Law collude to assure it.
The trail of semantic tears is simply what happens when people, not computers, make language and are its primary consumers. Despite mediation by browsers, it's pretty clear that HTML is designed for (some) humans and its visual semantics are all about what humans want. The issue with academic approaches to semantics are that they aren't borne of the crucible of inter-generational semantics. It's possible to describe everything in one generation -- perhaps even to get everyone to use some subset of langauge the same way, but what about when time passes? The real problem of web semantics is the probabilistic nature of meaning, and it can't be elided by tighter local descriptions, only a more global view to use.
Semantic Drift
If you've done time in the SQL mines of a major (read: old) company, you know how innocently it all starts: a problem was described, a schema was created, data was populated, and now it can't (really) change. Bits are packed into fields they don't belong in because re-normalizing isn't possible for organizational reasons. This is only the most technical version of what happens when language hits reality: if the words we use are useful at all, they soon get stretched. They get contextual meanings they didn't have before. They evoke other concepts and are taken on joy-rides by communities with their own jargon. In short, they drift slowly away from their original meanings (to the extent they ever have such things) to mean both more and less at the same time.
HTML is no different. Why should it be? What does <b>mean? Is it presentational? Can we make a case for it that isn't? The tighter the fit of the initial data model, the stronger the instinct to drift. Words, after all, are fluid. Yes, we look like idiots to everyone in earshot if we say "pigeon" to mean "pumpkin", but when enough people take the meaning and start using it, the inevitable drift takes hold.
Cutting to the chase, I submit for your consideration the idea that you can't have correct ontologies. Not for very long anyway. Any that are useful will be pressed into service outside their small-ish hometowns and will take on contextual meanings that aren't immediately obvious to speakers of the original dialect.
This is what it means for language to succeed. Systems of semantics and processing that cannot deal with, or do not anticipate, this sort of drift and growth are doomed. Language can be prevented from drifting only through the process of ending its widespread use.
Latin doesn't accumulate much new meaning these days.
Also, nobody speaks it.
This is not a coincidence.
Browser Vendors
The motives of browser vendors are actually the easiest to understand. It requires a subtle, non-market version of "competitive" and understanding that vendors promote browsers which have brands and marketing budgets but which happen to also come with rendering engines which have none of those things. Why? Because rendering engines don't make you any money -- best case scenario, the browser vendor is also a platform vendor and wants to use web technology as a platform play, but that's got precious little to do with browsers.
The key thing to understand about rendering engine teams, the standards nerds who toil around their edges, and the (primarily) C++ engineers who make it all work is that most of them don't build web sites. Neither do their customers (end-users). Most browser engineers get their information about what's a good or bad idea to implement secondhand. The most potent form of this is "our competition implemented something". The next most potent is "there's a spec for it". The least is "it's a great idea that solves this problem". Does that sound backwards? Think about the incentives: if you're not a profit center, what's in it for you to stick your neck out for a feature which you can't really differentiate your product with (save, perhaps, the cumulative experience of performance). Web developers mediate the experience of your rendering engine to end-users, and almost no web developer will jump to use new (aka "proprietary") features exclusively. To break the stalemate, vendors look for signs that the risks have been lowered: competition and specs. If the other folks did it, it's probably safe, and you don't want to be the last one. And if there's a spec, it probably went through some iteration to take the crazy edges off (would that were true!).
The most important thing to remember here is that, despite being the ones with all the power and the ability to enable new semantics, browser engine vendors derive the very least value from web semantics. This might get better as engines begin to self-host more features on top of JS, ShadowDOM, etc. I don't recommend holding one's breath.
Semantic Evolution
A coherent thesis of web platform evolution comes into view. It must:
Enable developers to build new end-user (visual & interactive) semantics when HTML's vocabulary is insufficient
Be meaningfully declarative, preferably by linking to other data/URLs to improve experience
Can be standardized over time
The last point is perhaps controversial: many a JavaScript library developer has asserted to me that if they can convince everyone to use a particular JQuery-based Date Picker (e.g.), why bother creating a standard version?
The case for standardization isn't that it will accelerate the adoption of new nouns/verbs, but rather than it can help disseminate them to new generations, thereby reducing their "cost" to use in conversation. This is the role that dictionaries play, and this is a meaningful role for HTML: once a semantic has proven value, is used relatively widely, and there's an agreed (visual, interactive, and declarative) semantic, HTML can canonize the most widely used set of meanings, thereby enabling browser vendors to adopt these canonical versions. On the web, that's the difference in performance between using a "free" built-in HTML element vs. the high price of adopting a widget from a library, all of its dependencies, and integrating that script into your applications. The words you can assume everyone else knows are the ones it's easiest to convey meaning with. HTML is a human language for humans, why should it be any different?
This is one of the motivators behind Web Components. By allowing developers to extend HTML's semantics directly, we stand a very real chance of making ad-hoc web semantics like those proposed at MicroFormats and Schema.org more meaningful -- first by enabling direct end-user value in the form of UI and second by enabling the sort of markup integration that allows search engines to make some sense of both of those priors.
Over the long haul, as libraries of widgets duke it out, coalesce, and become "de-facto standards", the slang can be cataloged. Not verbatim, of course. The exact form of <person> or <place> would likely going to drop a library-based prefix (<polymer-person>, e.g.) and the built-in UI would lose some configuration in exchange for system integration (places could pull up maps, people could interact with the address book). This is the sort of deal that gives browsers something meaningful to do, and with extensibility at the core of this ecosystem, this process can form a hierarchy where fads and data types evolve (and die out) quickly at the edges, but those which survive and become truly common will eventually be worth of inclusion in "the dictionary" -- the living HTML spec.
Isn't this all going to lead to a modern-day Babel?
Anything is possible, but it's not likely; at least not as long as the dictionary keeps up with the language we use. If HTML and browsers continue to integrate new nouns and verbs that solve real problems, the advantages that a shared vocabulary have over long-form descriptions create huge dis-incentives to continuing to use custom solutions. The power of fewer bytes-on-the-wire and browser-blessed optimizations create huge unifying waves that can allow us to continue to evolve the language around the edges as necessary without fear of devolving into mutually unintelligible sub-dialects.
We've proven over and over again that the HTML spec process works best when it can round off sharp edges of extant good ideas, rather than carrying the burden for inventing them all in the first place. Enabling an ecosystem of people to invent, iterate, and distribute new web semantics is my greatest hope for Web Components. It's one of the things that caused me to want to work on them in the first place, and now that they're nearly upon us, it's time to start thinking about what's next. How will we learn from them? How will we encourage useful semantics, now that we're free of HTML's 3rd-grade vocabulary? How will we grow HTML responsibly into the adult platform, based on evidence and respect for user experiences, that we all want it to become?
That's our challenge. We must view epochs in the web not as things to which we are subject, but a landscape which, should we set the rules right, we can shape quickly for ourselves and slowly for everyone else.