The web standards process fails us too often. This series explores the forces at work, how we're improving the situation, and how you can shape new features more effectively.
"Part 1: The Lay of The Land" discussed persistent challenges in standards and forces that give rise to misunderstandings. It also described the ecosystem dynamics that make change difficult, even before considering the varying firm-level strategies of browser vendors.
Making progress on new features is extraordinarily challenging in this environment. However, armed with a clear understanding of the situation, it's possible to chart a narrow but reliable path forward. Necessary ingredients in solving problems on the web platform include:
The ability to fail cheaply ...at least early on. Most ideas and designs aren't good, and most of the ones we eventually accept don't start good. Spaces that allow ideas to spring to life and quietly pass into time, or radically change without undue drama, are essential to improving our outcomes.
Participation by web developers and browser engineers Nothing good happens without both groups at the table.
A venue outside a chartered Working Group in which to design and iterate Pre-determined outcomes rarely yield new insights and approaches. Long-term relationships of WG participants can also be toxic to new ideas. Nobody takes their first tap-dancing lessons under Broadway's big lights. Start small and nimble, build from there.
A path towards eventual standardisation Care must be taken to ensure that IP obligations can be met the future, even if the loose, early group isn't convened with a strict IP policy
Face-to-face deliberation I've never witnessed early design work go well without in-person collaboration. At a minimum, it bootstraps the human relationships necessary to jointly explore alternatives.
It's attractive to think that design can (or should) happen within a formal Working Group. A well-functioning WG should include both developers and implementers, after all. Those groups often have face-to-face meetings, and the path toward standardisation is shortest in those venues! But it doesn't work; not often enough to be useful, anyway.
Starting your journey there leads to pain and failure. Why? The deck is stacked against design-in-committee, both structurally and procedurally.
Structurally, it is the job of a Working Group to evaluate proposals for inclusion in a specification. The basis for inclusion in nearly all standards I know of is not rigorous or scientific. Evidence is not (yet) a compelling argument. The norms of standards organisations are set, largely, by social cohesion amongst those working to improve the systems they maintain. The older the specification and the more stable the composition of the group, the harder it is for new ideas and people to enter with credibility.
A further difficulty for non-implementers (in another universe, "customers") within these groups is the information asymmetry inherent in the producer/consumer relationship. Implementers feel a responsibility to resist designs they feel would be detrimental to either their architecture or their competitive position. New ideas have to enter this environment roughly "done" to even get on the agenda.
Procedurally, it's the responsibility of chairs and the overall group to make progress towards the promised deliverables. Working Group charters typically set up a scoped set of deliverables and a time-table, and while there's lots of play built into these things, groups that don't continue to produce new versions on a regular basis are considered problematic. Problematic groups tend not to continue to receive the organisational support they require to continue.
Failure and iteration are the lifeblood of good design, but these groups are geared for success. They aggressively filter out new ideas to preserve their ability to ship new versions of specs. Once something is locked into a WG agenda, it's "in". This is inherently anti-iteration.
If you've never been to a functioning standards meeting, it's easy to imagine languid intellectual salons wherein brilliant ideas spring forth unbidden and perfect consensus is forged in a blinding flash. Nothing could be further from the real experience. Instead, the time available to cover updates and get into nuances of proposed changes can easily eat all of the scheduled time. And this is expensive time! Even when participants don't have to travel to meet, high-profile groups are comically busy. Recall that the most in-demand members of the group (chairs, engineers from the most consequential firms) are doing this as a part-time commitment. Standards work is time away from the day-job, so making the time and expense count matters. Before anyone gets into the room, everyone knows what the important topics will be, and if precious time is taken from resolving those issues — particularly to explore "half baked" ideas — influential folks (and the teams they represent) will be upset. Not a recipe for agreement.
The idea that a public, agenda-driven, minuted, chaired forum with a full docket and a room full of powerful decision-makers primed to say "no" is where your best design work will happen is barmy. Policies aren't dreamt up in open session at Parliament, Congress, or the UN; rather they're presented and voted on, possibly with minor amendments.
Note: There are many dysfunctional standards groups; they tend to have lighter agendas or a great deal of make-work. Those groups are unlikely to be well-attended by busy implementers. Groups that can't keep implementer interest aren't worth investing time in.
This insight is why the Chrome team now insists on doing design work in "incubation" forums. These can be embedded into a WG's formal process (as at TC39), or in separate forums which are feeders for formal, chartered groups (e.g. WICG or RICG).
What I've learned over the past decade trying to evolving the web platform is a frustratingly short list given the amount of pain involved in extracting each insight:
Do early design work in small, invested groups
Design in the open, but away from the bright lights of the big stage
Iterate furiously early on because once it's in the web, it's forever
Prioritize plausible interoperability; if every implementer says "that can't work", believe them. [1]
Ship to a limited audience as soon as possible to get feedback
Drive standards with evidence and developer feedback from those iterations
Prioritise interop over perfect specs; tests create compatibility as much or more than tight prose or perfect IDL
Dot "i"s and cross "t"s; chartered Working Groups and wide review are important ways to improve your design later in the game
These derive from our overriding goal: ship the right thing.
All too often we've seen designs (coughAppCachecough) that could have been improved by listening to available feedback. Design processes without web developers involved tend to fail because they can't error correct. Implementers most acutely feel the constraints of their system, not web developer reality. Without the voices of web developers, designs tend towards easy-to-build — rather than fit-for-purpose. Group-think too often takes hold, as those represented share the same perspective, making change and iteration harder.
Similarly, design efforts without implementers present are missing the constraints that lead to successful design. Proposals without this grounding are easily written off. It's tempting to get a group together to design future APIs in a vacuum, but without implementers critical mass never forms.
So how can you shape the future of the platform as a web developer?
The first thing to understand is that browser engineers want to solve important problems, but they might not know which problems are worth their time. Making progress with implementers is often a function of helping them understand the positive impact of solving a problem. They don't feel it, so you may need to sell it!
Building this understanding is a social process. Available, objective evidence can be an important tool, but so are stories. Getting these in front of a sympathetic audience within a browser team is perhaps harder. Thankfully, functional browser engine teams now staff sizable outreach and Developer Relations groups (oh hai, @ChromiumDev, @mozappsdev, MSEdgeDev, and Jonathan!). Similarly, if you happen to work for a top-1k web property, your team may already have a connection to a browser's partnerships team. Those teams can route thoughtful questions to the right engineers.
Other models for early collaborations involve sideline conversations at industry gatherings, e.g. TPAC or BlinkOn. Special-purpose vehicles like W3C Workshops are somewhat harder to organize, but browser engineers are willing to join them. I can't speak for other vendors, but Chromies are also willing to travel for ad-hoc gatherings to do early design work. Andrew Betts masterfully orchestrated such an event while at the FT, kicking off what became Service Workers. You might not have Andrew's wealth of connections, but odds are you probably know someone who does. Remember, at the start this is about individuals. Drawing attention to an issue that you think is important means building a small group of like-minded folks. It's effort to find "your people", but it's far from impossible!
Next, recognize that the design, development, iteration, and eventual standardisation phases take time. Sometime a lot of time. As a web developer, it's unlikely that you'll be able to sustain professional interest in such a process as there's no practical way it can bear fruit in time for your current (or even next) project. This is not a personal failing, it's just how the gearing works. You have information that browser teams don't, but less leverage and time. Setting them on a better course is helping the next person and, if you're doing this as your profession, may eventually help you too. Don't feel guilt for needing to drop out of the process at some point.
It has gotten ever easier to stay engaged as designs iterate. After initial meetings, early designs are sketched up and frequently posted to GitHub where you can provide comments. Forums like WICG let you provide direct design feedback during development — a very intentional shift by the Chrome and Edge teams to give developers a louder voice when designs are still maleable.
Further along the process, Chrome is now running a series of "Origin Trials", an idea the Chrome team borrowed from Jacob Rossi at MSFT. Origin Trials allow developers to test new features on live sites and shape their evolution. Teams running these trials actively solicit feedback and frequently change them in response.
Astute readers will note none of this involves joining a Working Group or keeping up with busy mailing lists. Affecting the trajectory of the web platform has never been easier, assuming you know which side of the amplifier to approach.
These relatively new opportunities for participation outside formal processes have been intentionally constructed to give developers and evidence a larger role in the design process. We've supported their creation because they help us to separate open design and iteration from standardisation, allowing each process to assist the community in improving features at the point where they are most effective.
These processes aren't perfect by any stretch, and it would be an epic understatement to suggest that the broader browser and standards communities agree with design via incubation outside of formal Working Groups. Maintenance work is a particularly thorny topic. Regardless, the Chrome team has gathered compelling evidence that this is a better way to work.
Prizing collaboration, iteration, and evidence has enabled us to shape process to support those values. Incubation and related processes let us be more responsive to developers while simultaneously increasing confidence that features shipped to Stable meaningfully address problems worth solving. Hopefully this series will help you shape the future with fewer misunderstandings. After all, we all want to see the right thing ship.
I've been drafting and re-drafting versions of this post for almost 4 years. In that time I've promised a dozen or more people that I had a post in process that talked about these issues, but for some of the reasons I cited at the beginning, it has never seemed a good time to hit "Publish". To those folks, my apologies for the delay.
There's a meta-critique of formal standards and the defacto-exclusionary processes used to create them. This series didn't deal in it deeply because doing so would require a long digression into the laws surrounding anti-trust and competition. Suffice to say, I have a deep personal interest in bringing more voices into developing the future of the web platform, and the changes to Chrome's approach to standards discussed above have been made with an explicit eye towards broader diversity, inclusion, and a greater role for evidence.
Sometimes an implementer will say "that can't possibly work" and then another one will show up with a working prototype that does exactly what the first claimed was impossible. In this situation, it's fine to discount folks who have been proven wrong.
It's hard from the outside to know why they were wrong, but they were. Sometimes, they might have even known a feature was possible but just want to do less work. Even if that's not the case, it's also reasonable to discount their (personal) future claims of impossibility. Implementers should be very, very careful when they claim something is impossible. ↩︎
The web standards process fails us too often. This series explores the forces at work, how we're improving the situation, and how you can shape new features more effectively.
"Why don't browsers match standards!" muttered the thoughtful developer (just before filing an issue at crbug.com). "The point of standards is so that everything works the same."
Once something is in The Standard, everyone will implement interoperably...right?
Maybe. Confusion about how interoperability is really created sparks many of the worst arguments I've witnessed in my ~12 years working on web platform features.
Not every effort I've been involved in has succeeded (e.g. ES4), while some have but took too long. A few even went well. Having made most of the available mistakes, I was handed the responsibility to keep Chrome engineers from error as our "Web Standards Tech Lead". I don't write about it much because anything said is prone to misinterpretation; standards-making is inherently political. In the interest of progress, this 2-part series is a calculated risk.
Some problems on the web can be solved in userland. Others require platform changes. For historical and practical reasons, changes to the web platform must be codified in web standards. The community of web developers and browser vendors share this norm. Browsers are substitutable and largely rival goods.
Every party has reasons to value compatibility and interoperability. Developers benefit when interop extends the reach of their products and services. Browsers benefit from interop as end-users abandon browsers that can't access existing services and content. New features, then, require a trajectory towards standardisation. Features shipped without corresponding standards proposals are viewed critically. For business folks primed to hear "proprietary" as a positive, it can be surprising to encounter the web community's loathing of non-standard features.
From far enough away, it may appear as though new features "happen" at the W3C or WHATWG or ECMA or IETF. Some presume that features which are standardised at these organisations originated within them — that essential design work is the product of conversations in committee. If vendors implement what standards say, then surely being part of the standards process is how to affect change.
This isn't how things work in practice, nor is it how feature design should work. Instead, new features and modifications are brought to Standards Development Organisations ("SDOs") by developers and vendors as coherent proposals. It's important to separate design from standards making. Design is the process of trying to address a problem with a new feature. Standardisation is the process of documenting consensus.
The process of feature design is a messy, exciting exploration embarked upon from a place of trust and hope. It requires folks who have problems (web developers) and the people who can solve them (browser engineers) to have wide-ranging conversations. Deep exploration of the potential solution space — discarding dozens of ideas along the way — is essential. A lot of the work is just getting to agreement on a problem statement. This is not what formal standards processes do.
TL;DR: SDOs and their formal Working Groups aren't in the business of feature design.
SDOs and Working Groups can't tell you if a design solves an important problem or solves it well. They are set up to pass judgement on the details of a specification and a consensus surrounding the specific words in spec documents.
Working Groups and SDOs are not fitness functions for features.
Getting a design through committee says next to nothing about its quality. Many an august and thoughtful person has engaged in outrageous groupthink when these processes are asked to predict the future rather than document consensus. Without developers trying a feature and providing feedback, Working Groups quickly wander into irrelevant pastures. And who's to tell them they're wrong? They are staffed with experts, after all!
SDOs are best understood as amplifiers: they take raw inputs, filter them to prevent major harm if played at top volume, then use processes to broadcast them. How the inputs came to be gets obscured in this process.
I can report these histories aren't lost, but they are unattractive. Participants have reasons not to tell them — boredom with a topic, the phantom pain of arguments nearly won, and the responsibilities of statesmanship towards counterparties. Plucky documentarians sometimes try, but standards dramas don't exactly jump off the page.
When the deeper histories aren't told or taught, it becomes hard for newcomers to get oriented. There's no effective counter-narrative to "progress come from standards bodies", and no SDO is going to turn down new members. Nobody tells developers not to look to SDOs for answers. Confusion reigns.
Feature design starts by exploring problems without knowing the answers, whereas participation in Working Groups entails sifting a set of proposed solutions and integrating the best proposals. Late iteration can happen there, but every change made without developer feedback is dangerous — and Working Groups aren't set up to collect or prioritise it.
Even when consensus is roughly achieved, standards processes are powerless to compel anyone to implement anything, even Working Group participants! Voluntary standards are not regulations. Implementers adopt standards because customers demand interoperability to hedge against vendor market power.
It can't be repeated enough: the fact of something appearing in a web standard compels nobody to implement, even those who implemented previous versions. This flows from the fundamental relationships between browsers, developers, and users.
Preventing abuse is one thing, but perhaps new features are different? A browser can add dozens of proprietary features, but if developers decline to adopt, users don't benefit. Developer adoption is frequently gated on interoperability, a proxy for "can I reach all the users I want to if my app requires this feature?" That is, developers often decline to use features that aren't already in every engine they care about.
Circularly, non-implementing engines view features without broad use as cost rather than potential benefit. This is particularly true when the alternative is to improve performance of existing features. A sure way for a browser engineer to attract kudos is to make existing content work better, thereby directly improving things for users who choose your browser. Said differently, product managers intuitively prefer surefire improvements to their products rather than speculative additions which might benefit competitors as much (or more). Enlightened ecosystem thinkers are rare, although the web has been blessed with several of them recently.
Last, but not least, a lack of solidarity looms over the enterprise. Browser engineers don't make websites for a living, so they also lack intrinsic motivation to improve the situation. Many an epic web standards battle to advance an "obviously" missing feature can be traced to this root.
Note: the whole ecosystem breaks down when users do not have a real choice of engine, e.g. on iOS. When competition is limited vendors are free to structurally under-invest and the platform becomes less dynamic and responsive to needs. Everyone loses, but it's a classic deadweight loss, making it harder to spot and call out.
The status quo is powerful. Every vendor has plausible (if played-up) reasons not to implement new features. They can stall progress until they are last (or second-to last in a 4+ party ecosystem) to implement. There's no developer wrath until that point, and it's easy to cast FUD on not-yet-pervasive features while holding a pocket veto. Further, it's the job of SDOs and formal Working Groups to kill ideas that are not obviously fit for purpose or which lack momentum.
This situation looks hopeless for folks trying to make progress. The slow pace of some essential but overdue improvements (Responsive Images, CSS variables, ES6 Classes, Promises & async/await, Web Components, Streams, etc.) would give any sane observer pause. Is it worth even trying?
The enormous positive impact that changes to the web platform can deliver makes me believe the answer is "yes". In Part 2 I'll share details of how the Chrome Team changed its thinking about feature development and standards and how that's enabling the entire web community to deliver more progress faster.
TL;DR: performance budgets are an essential but under-appreciated part of product success and team health. Most partners we work with are not aware of the real-world operating environment and make inappropriate technology choices as a result. We set a budget in time of <= 5 seconds first-load Time-to-Interactive and <= 2s for subsequent loads. We constrain ourselves to a real-world baseline device + network configuration to measure progress. The default global baseline is a ~$200 Android device on a 400Kbps link with a 400ms round-trip-time ("RTT"). This translates into a budget of ~130-170KB of critical-path resources, depending on composition -- the more JS you include, the smaller the bundle must be.
We've had the pleasure of working with dozens of teams over the past few years. This work has been illuminating, sometimes in very unexpected ways. One of the most surprising results has been the frequent occurrence of "ambush by JavaScript":
We need a new term for the business-opportunity wastage that modern front-end development has created.
Maybe "ambush by JS"?
Business leaders who green-light the development of Progressive Web Apps frequently cite the ability to reach new users with near-zero friction as a primary motivator. At the same time, teams are reaching for tools which make achieving this goal impossible. Nobody is trying to do a poor job, and yet the results of a "completed" PWA project often require weeks or months of painstaking rework to deliver minimally acceptable performance.
This rework delays launch which, in turn, delays gathering data about the viability of a PWA strategy. Teams we aren't able to work with directly sometimes do not catch these problems until it's too late, launching experiences which are simply unusable for all but the wealthiest.
Teams that avoid unpleasant surprises tend to share a few traits:
Executive sponsors are enthusiastic. They use "do what it takes" language to describe the efforts to get and stay fast
Performance budgets are set early in the life of the project
Budgets are scaled to a benchmark network & device
Tools and CI systems help them monitor progress & prevent regressions
These properties build on each other: it's difficult to get the space you need to plan to do things well without decision makers who value user experience and long-term business value. Teams with this support are free to set performance budgets, do "bakeoffs" between competing approaches, and invest in performance infrastructure. They're also more able to go against the "industry standard" grain when popular tools prove to be inappropriate.
Performance budgets keep everyone on the same page. They help to create a culture of shared enthusiasm for improving the lived user experience. Teams with budgets also find it easier to track and graph progress. This helps support executive sponsors who then have meaningful metrics to point to in justifying the investments being made.
Budgets set an objective frame for determining which changes to the codebase represent progress and which are regressions from the user perspective. Without them it's impossible to avoid slipping into the trap of pretending you can afford more than you can. Very rarely have we seen a team succeed that doesn't set budgets, gather RUM metrics, and carry representative customer devices.
Partner meetings are illuminating. We get a strong sense for how bad site performance is going to be based on the percentage of engineering leads, PMs, and decision makers carrying high-end phones which they primarily use in urban areas.
Doing better by users involves 2 phases:
Challenging assumptions & growing understanding of real-world conditions
Automating testing against an objective baseline
Never before have front-end teams enjoyed access to such good performance tools and diagnostic techniques, yet poor results are the norm. What's going on here?
One distinct trend is a belief that a JavaScript framework and Single-Page Architecture (SPA) is a must for PWA development. This isn't true (more on that in a follow-up post), and sites which are built this way implicitly require more script in each document (e.g., for router components). We regularly see sites loading more than 500KB of script (compressed). This matters because all script loading delays the metric we value most: Time to Interactive. Sites with this much script are simply inaccessible to a broad swath of the world's users; statistically, users do not (and will not) wait for these experiences to load. Those that do experience horrendous jank.
Late-loading JavaScript can cause "server-side rendered" pages to fail in infuriating ways. This uncanny-valley effect is the reason we focus on when pages become reliably interactive.
Consider a page like:
The browser encounters this document in response for a GET request to https://example.com/. The server sends it as a stream of bytes and when the browser encounters each of the sub-resources referenced in the document, it requests them.
For this page to be done loading it needs to be responsive to user input -- the "interactive" in "Time to Interactive". Browsers process user input by generating DOM events that application code listens to. This input processing happens on document's main thread, where JavaScript runs.
Here are some operations that can happen on other threads, allowing the browser to stay responsive:
Parsing HTML
Parsing CSS
Parsing and compiling JavaScript (sometimes)
Some JS garbage collection tasks
Parsing and rasterizing images
GPU-accelerated CSS transformations and animations
Main-document scrolling (assuming no active touch listeners)
These operations, however, must happen on the main thread:
Execution of JavaScript
Construction of DOM
Layout
Processing input (including scrolling w/ active touch listeners)
If our example document wasn't reliant on JavaScript to construct the <my-app> custom element, the contents of the document would likely be interactive as soon as enough CSS and content was available to render meaningfully.
Script execution delays interactivity in a few ways:
If the script executes for more than 50ms, time-to-interactive is delayed by the entire amount of time it takes to download, compile, and execute the JS
Any DOM or UI created in JS is not available for use until the script runs
Images, on the other hand, do not block the main thread, do not block interaction when parsed or rasterized, and do not prevent other parts of the UI from getting or staying interactive. Therefore, while a 150KB image won't appreciably increase TTI, 150KB of JS will delay interactivity by the time required to:
Request the code, including DNS, TCP, HTTP, and decompression overhead
Parse and compile the top-level functions of the JS
Execute the script
These steps are largely serialized.
If script execution could stay under 50ms for a bundle this large, TTI would not be delayed, but that's not feasible. 150KB of gzipped JavaScript expands to roughly 1MB of code, and as Addydocumented, that's going to take more than a second on most of the world's phones not including the time to fetch it.
JavaScript is the single most expensive part of any page in ways that are a function of both network capacity and device speed. For developers and decision makers with fast phones on fast networks this is a double-whammy of hidden costs.
Deciding what benchmark to use for a performance budget is crucial. Some teams and businesses know their audience intimately and can make informed estimates about the devices and networks current and prospective users are on. Most, however, do not have such a baseline easily to-hand. Where to start?
The median user is on a slow network. Just how slow is a matter of some debate.
Our metrics at Google show a conflicted picture (which I'm working to get to clarity on). Some systems show median RTTs near ~100ms for 3G users. Others show the median user unable to transmit and receive an individual packet in less than 400ms in some major markets.
Googlers enjoy access to a simulated "degraded 3G" network to help validate the behaviour of their apps under these conditions. It simulates a link with a 400ms RTT and 400-600Kbps of throughput (plus latency variability and simulated packet loss). Given the conflicted data we see across our other systems, this seems about right as a baseline.
Simulated packet loss and variable latency, however, can make benchmarking extremely difficult and slow. The effect of a lost packet during DNS lookup can be a difference of seconds, making it frustrating to compare before/after for changes at development time. Our baseline, then, should probably trade lower throughput/higher-latency for packet loss. What we lose in real-world fidelity, we gain in repeatability and the ability to compare across changes and across products. There's much, much more to say about the effects of DNS, TLS, network topology, and other factors. For those who want to go deeper on this, I highly recommend Ilya Grigorik's "High Performance Browser Networking". The coverage of RRC alone makes it worth your time.
Back to our baseline, we now have a sense for what our simulated network conditions should be: 400ms RTT, 400Kbps bandwidth. What about the device itself?
The true median device from 2016 sold at about ~$200 unlocked. This year's median device is even cheaper, but their performance is roughly equivalent. Expect continued performance stasis at the median for the next few years. This is part of the reason I suggested the Moto G4 last year and recommend it or the Moto G5 Plus this year.
Putting it all together, our global baseline for performance benchmarking is a:
~$200 (new, unlocked) Android phone
On a slow 3G network, emulated at:
400ms RTT
400Kbps transfer
For most technologists, building applications for this environment might as well be farming on Mars. Luckily, this configuration is available on webpagetest.org/easy, meaning we can re-create these conditions here on earth, any time we like.
The Monica Perf Test™: if you wouldn't make eye contact with a stranger for the time it takes your web app to first paint, it's too slow.✌️💫
...but that's more qualitative than quantitative. Numerically, we'd prefer every page load occur in under a second (see RAIL). That's not possible on real-world networks, so we've set the following Time-to-Interactive (TTI) metric goal with partners:
Working backwards from time, network conditions, and the primary stages of the critical path, we get a few interesting results. We can start with our first-load budget of 5 seconds and begin to calculate how much transfer we can afford.
First we subtract 1.6 seconds from our budgets for DNS lookup and TLS handshaking, leaving us 3.4s to work with.
Then, we calculate how much data we can send over this link in 3.4 seconds: 400 Kbps = 50KB/s. 50KB/s * 3.4 = 170KB.
NOTE: This discussion is sure to infuriate competent network engineers. Previous versions of this article discussed slow-start, bdp, tcp window scaling, and the like. They were commensurately difficult to follow. Simplifying has relatively little impact on the overall story, so those details are elided.
Modern web applications are largely composed of JS, meaning we also need to subtract the amount of time the JS needs to parse and evaluate. The gzip compression factor for JS code is between 5x and 7x. 170KB of JS then becomes ~850KB-1MB of JS which, based on earlier estimates, may take a second to run (presuming it doesn't do any expensive DOM work, which of course it will). Playing with these numbers a little bit, we can get back below 3.4s of download and eval by limiting ourselves to 130KB of JS transferred on the wire.
One last wrench in the works: if any of our critical-path resources come from a different origin (e.g., a CDN), we need to subtract connection setup time for that origin (~1.6s) from the budget, further limiting how much of our 5s we actually get to can spend on network transfer and client-side work.
Putting it all together, under ideal conditions, our rough budget for critical-path resources (CSS, JS, HTML, and data) at:
170KB for sites without much JS
130KB for sites built with JS frameworks
This gives us the ability to consider the single most pressing question in front-end development today: "can you afford it?"
For example, if your JS framework takes ~40KB of transfer on a JS-heavy site (which gets a budget of 130KB thanks to JS eval time), you're left with only 90KB of "headroom". Your entire app must fit into that space. A 100KB framework loaded from a CDN is already 20KB over budget.
Think back: your framework of choice might be 40K, but what about that data system? The router you added? Suddenly 130KB doesn't seem like a lot when you also need to include data, templates, and styles.
Living on a budget means constantly asking yourself "can I really afford this?"
In an ideal world, all page loads happen in under a second, but for many reasons that's often not feasible. Therefore we're going to give ourselves a bit of a breather and budget 2 seconds for second (third, fourth, etc.) load.
Why not 5? Because we shouldn't need to ever go to the network to get our app's UI booted once we've visited it the first time. Service Workers and "offline first" architectures enables us to put interactive pixels on screen without ever touching the network. This is the key to achieving reliable performance.
Two seconds is forever in modern CPU terms, but we still need to spend it wisely. Factors we need to account for include:
Process creation time (Android is relatively slow vs. other OSes)
Time required to read bytes from disk (it's not zero, even on flash-based storage!)
Time to execute and run our code
Every app I've seen that hits a 5s initial load and implements offline-first correctly stays under this 2s budget, and sub 1s is possible! But getting to offline-first is a huge challenge for many teams. Architecting to save last-seen user data locally, cache app resources in a reliable and coherent way, and juggle application code upgrades using the Service Worker lifecycle can be a major undertaking.
I'm looking forward to tools continuing to evolve in this area. The most comprehensive bootstrap I know of today is the Polymer App Toolbox, so if you're not sure where to start, start there.
Many teams we talk to wonder if it's even possible to deliver something useful in as little as 130KB. It is! the PRPL pattern shows the way through aggressive code-splitting based on route awareness, Service Worker caching of granular (subsequent-page) resources, and clever use of modern protocol enhancements like HTTP/2 Push.
Sadly, it's still sort of difficult to tell from a specific trace which parts of the page load are critical-path resources for TTI and which aren't, but I'm optimistic that tools will evolve quickly to help us understand this key metric.
Regardless, we know it's possible, even without giving up on frameworks entirely. Both Wego and Ele.me are built with modern tools (Polymer and Vue, respectively) and help users complete real transactions today. Most apps are less complex than they are. Life on a budget isn't starvation.
Getting under-budget is hard, but the benefits to the business and to users are immense. Less often discussed are the benefits to engineering teams and their leaders. No tech-lead or PM wants to be on the wrong side of an executive who walks into their area with a phone asking "so why is this so slow when I'm on vacation?"
This isn't theoretical.
I've seen teams that have just finished re-building on a modern tech stack cringe for an hour as we walk them through the experience of using their "better", "faster" experiences under real-world conditions.
Everyone loses face when the product fails to meet expectations. Months of unplanned performance fire-fighting delay the addition of new features and have a draining effect on team morale. When performance becomes a crisis, mid-level managers get caught between being the "shit umbrella" their teams count on and crushing self doubt. Worse, they may begin to doubt their team. The other side of a performance crisis is a long road; how can the organisation trust the team to deliver a quality product? Can they trust the TLs to recommend new technology or large re-investments? Recriminations follow. This is a terrible experience, specifically for developers who are too often on the receiving end of incredible pressure to "fix it", ASAP -- and "it" may be a core technology the product is built on.
In the worst cases, the product may be unfixable on a short enough timeframe to help the business. A lot of progress is Darwinian and for startups and small teams, betting on the wrong stack without the benefit of a long runway can be fatal. Worse, this can go un-diagnosed for a long, long time. If the whole team carries the latest iOS devices on fast, urban networks and the product's economics are premised on growing a broad-based audience, the failure of that audience to arrive barely makes a sound.
Performance isn't the (entire) product, of course. Lots of slow or market-limited products do incredibly well. Having a unique service that people want (and will go out of their way for) can override all of these other concerns. Some folks even succeed in App Stores where friction-to-acquire an experience is intense. But products in competitive marketplaces need every advantage.
Some specific tools and techniques can help teams that adopt a performance budget:
WPT scripting: for teams that don't want to set up a custom WPT instance and have public URLs for their WIP apps, integrating with WPT scripting can be a great way to get regular "checks"
WPT private instances: teams that want to integrate WPT directly into their CI or commit-queue systems should investigate setting up a private WPT server and hardware
Scripted Lighthouse: not ready for a full WPT instance? Scripting Lighthouse can help your CI automate analysis of your site and catch regressions
grunt-perfbudget is an even-easier, automated WPT testing for your CI. Use it!
Speedcurve and Calibre: these hosted services automate tracking performance over time, delivering an outstanding real-world gut-check
Webpack Performance Budgets: for teams using webpack in their build steps, enabling this configuration can provide great development-time warning for resources that exceed budgets.
bundlesize and pr-bot let you set per-script budgets which can be automatically enforced as part of your pull-request process. Recommended!
Success in combating bloat often means turning warnings into hard errors. Teams with CI or commit-queue systems should strongly consider disallowing commits that break the (performance) bank.
For teams starting fresh, my strong recommendation is to start with a stack that embeds strong opinions about app structure, code splitting, and build targets. The best of those today are:
Next.js, preferably using Preact as a lighter-weight runtime library
Whatever tools your team chooses, a budget is essential. Without one, even the most advanced, "lightweight" frameworks can easily create bloated, unusable apps. Starting from the global baseline and only increasing the budget based on hard numbers is the best way I know of to ensure your project lands well for everyone.
In the interest of time and space, discussion of future-friendly architectures will have to wait for another post. The curious can dig into Service Workers, Navigation Preload, and Streams. Their powers combined are going to fundamentally transform the optimal page-load for 2018 and beyond.
Lastly, thanks to everyone who reviewed early drafts of this post, including (but not limited to): Vinamrata Singal, Paul Kinlan, Peter O'Shaughnessy, Addy Osmani, and Gray Norton. Hopefully their valiant attempts to direct this article away from error were not overcome by my talent in adding it.
Dimitri Glazkov, Alex Komoroske, and I started the project that designed and (for many years) iterated on Web Components with a few primary goals in mind:
Enhance component portability
Shrink the amount of infrastructure code required over-the-wire and at runtime
Enable the browser to optimize components
All of this was wrapped up in our project's mantra: "say what you mean".
Our position was (and is) that developers shouldn't need to write the word function when they meant class or module and they shouldn't have to type <div class="tree-control"> or torture existing HTML elements to "mean" something they clearly did not. JavaScript programmers should be able to instantiate components naturally (new TreeControl(...)) and that shouldn't need to be an exclusive choice that implicitly forces web developers to pick JS over HTML or vice versa. A componentized future should not exclude those who compose UIs in HTML. That means components need to participate in the built-in deserialization system: the HTML parser.
Web developers shouldn't need build steps or an expensive runtime systems to re-create parsing. Nor should typing <tree-control> in your markup require a specific framework to "fake" parser integration with custom, per-framework timing and lifecycle management (a source of much incompatibility).
When we started the "Parkour" project in 2010, members of the team had built something like a dozen JavaScript frameworks or component systems between them and those systems were powering the front-ends of billion-dollar businesses and used by thousands of engineers every day.
None of them could meaningfully share components or code.
Each of these tools became inadvertently totalizing when used at scale. The cost of the framework code was a major concern, and pulling in components from different frameworks implied pulling in all of the support code required to bootstrap the component models of each system. Maybe that would be palatable for a particularly juicy component (data grid, anyone?), but interop was more frequently stymied by the need to wrap components. The decision of which abstraction to interoperate on implicitly creates a situation where teams must pick "their" framework and then make components from other systems work within those terms.
It doesn't take a lot of familiarity with the history of JS frameworks to note a wide diversity amongst successful tools on a number of important axes: the most productive and efficient way to instantiate components, how and when configuration takes place, how data and configuration are updated, the lifecycle of the component, ownership of (and access to) managed DOM nodes, markup integration, and much more. Templating systems are relatively pluggable, but the thing about frameworks is that they set the terms of everything that happens in components. When frameworks make different choices (and they do), compatibility is the first casualty.
At this drilled-in level, we will no doubt endlessly debate these choices. Businesses trying to make durable investments, however, are forgiven for growing weary of the predictable outcomes: teams decide on the "best" tool, invest heavily in building (or using) components, only to discover that the next app or the next team makes a different choice. This creates a compatibility quandary as soon as anyone wants to re-use anything. Just upgrading from Version N of a framework to Version N+1 frequently creates this sort of problem. The painstaking work of building accessibility, shared styles, and reasonable performance into components often looks like good money after bad.
At a fundamental level, this happens because when JavaScript is the component model, all the choices are up for grabs. It might seem like there's some "lower level" interop to be gained by modeling everything in pure JS (not DOM), but this is a mirage. I'm not sure what the correct model is for this recipe for incompatibility, but the complexity of achieving compat seems intuitively to be O(N^2) or worse. Every major decision represented within a framework makes reaching compatibility with another framework exponentially harder. This is multiplied by the set of hopefully-interoperable frameworks.
Finally, the incentives of framework authors are not aligned with compatibility. Competition between JavaScript frameworks is fierce, and every tool that thinks it will "win" has a natural inclination to grow the set of components that are exclusive to the framework. A large, high quality control set is a compelling selling point, after all.
There are also costs associated with compatibility. First, compatibility requires stability and a commitment to a specific design. This ham-strings framework authors who (rightly) value the ability to change their minds and adapt to better ways of approaching problems. Second, the overhead of compatibility testing for the matrix of frameworks detracts from other priorities (performance, accessibility, "developer experience") that frameworks are judged on; particularly at adoption time. Where would this time-consuming work take place? Conference calls? How often? Who's organising and paying for it?
No matter how much businesses want the ability to reuse components, JavaScript frameworks as we know them are never going to deliver interop. It's called "framework churn" and not "component mixing" because to adopt the new thing the old one must be plowed under.
It's sobering to think that the endless framework churn has been with the JavaScript community for as long as we've been writing sizable apps. For me, that's more than 15 years. The evidence has been heard and verdict is in: there is no such thing as component longevity with interoperability so long as our abstraction is JS.
The deep reason for this is that all modern JavaScript UI frameworks manage two trees:
The logical tree of high-level components ("widgets") which developers use to construct their applications
An internal tree of managed DOM for each widget
Frameworks are in the business of providing the abstraction for the logical tree, a system for creating and managing widget internals, and (most importantly), systems for preventing widget internals from leaking into the logical tree. Until now, the only game in town for creating this encapsulation has been to create a tree that's parallel to the one exposed in the DOM.
Before the arrival of Shadow DOM, there was no way to avoid airing all of a component's dirty laundry (managed DOM) in the overall tree structure of the document. Component authors need to operate on the bits of DOM that they "own" and manage, whereas component users usually want to avoid seeing, touching, or interfering with the implementation details of the components they're composing into an app.
Custom Elements and Shadow DOM eliminate the need for a separate tree and traversal system. Together, they allow the developer to surface their component as a first-class citizen within the existing contract (HTML and the resulting DOM) whilst hiding the implementation details from casual traversal and interference. This is a trick that the built-in elements (think <video> or <select>) have been able to do forever, but until now it has not been available to us muggles.
Web Components represent something fundamentally different from the status quo. No other approach is able to actually eliminate the need for parallel trees.
The kicker is that Web Components are a web standard. The half-decade argument about what the lifecycle methods should be called, what they should do, and how it should all fit together has concluded. What's shipping in Chrome and Safari and Opera and Samsung Internet and UC Browser today is not something that can change easily (for better and for worse). This is a contract that a major fraction of the web relies on; it cannot be removed. The browsers that haven't shipped yet are under hugepressure to do so.
In the talk I gave a few weeks back at the Polymer Summit, I went into detail about the performance motivations for some of the original Parkour work:
One of the best outcomes from delegating our component model to the platform is that, when we do, many things get cheaper. Not only can we throw out the code to create and manage separate trees, browsers will increasingly compete on performance for apps structured this way. Work over the past year in Chromium has already yielded significant speedups for Custom Elements and Shadow DOM, with more on the way. Platform-level scoping for CSS via Shadow DOM has enabled sizable memory and compute wins for style resolution, and overall re-architecture of the system benefits custom elements in ways that user-space won't benefit from as significantly.
Ignoring all of that, Mikeal's core point resonates strongly:
Our default workflow has been complicated by the needs of large web applications. These applications are important but they aren’t representative of everything we do on the web, and as we complicate these workflows we also complicate educating and on-boarding new web developers.
One of the things we'd hoped to enable via Web Components was a return to ctrl-r web development. At some scale we all need tools to help cope with code size, application structure, and more. But the tender, loving maintenance of babel and webpack and NPM configurations that represents a huge part of "front end development" today seems...punitive. None of this should be necessary when developing or using one (or a few) components. Composing things shouldn't be this hard. The sophistication of the tools should be proportional to complexity of problem at hand. Without a common component model, that will never be possible.
Since Frances and I published a blog post last year introducing Progressive Web Apps, a healthy conversation has started about what is and isn't a PWA. There are a lot of opinions and many shades of gray. What are the hard requirements? Which requirements are marginal? What's aspirational? This article outlines these requirements, attempts to classify them, and provides a baseline for "what is a Progressive Web App?"
Browsers gate Progressive Web App installation prompting and badging on criteria that they detect when users navigate to sites. These criteria have been designed to ensure that sites which invoke prompts are reliable, fast, and engaging.
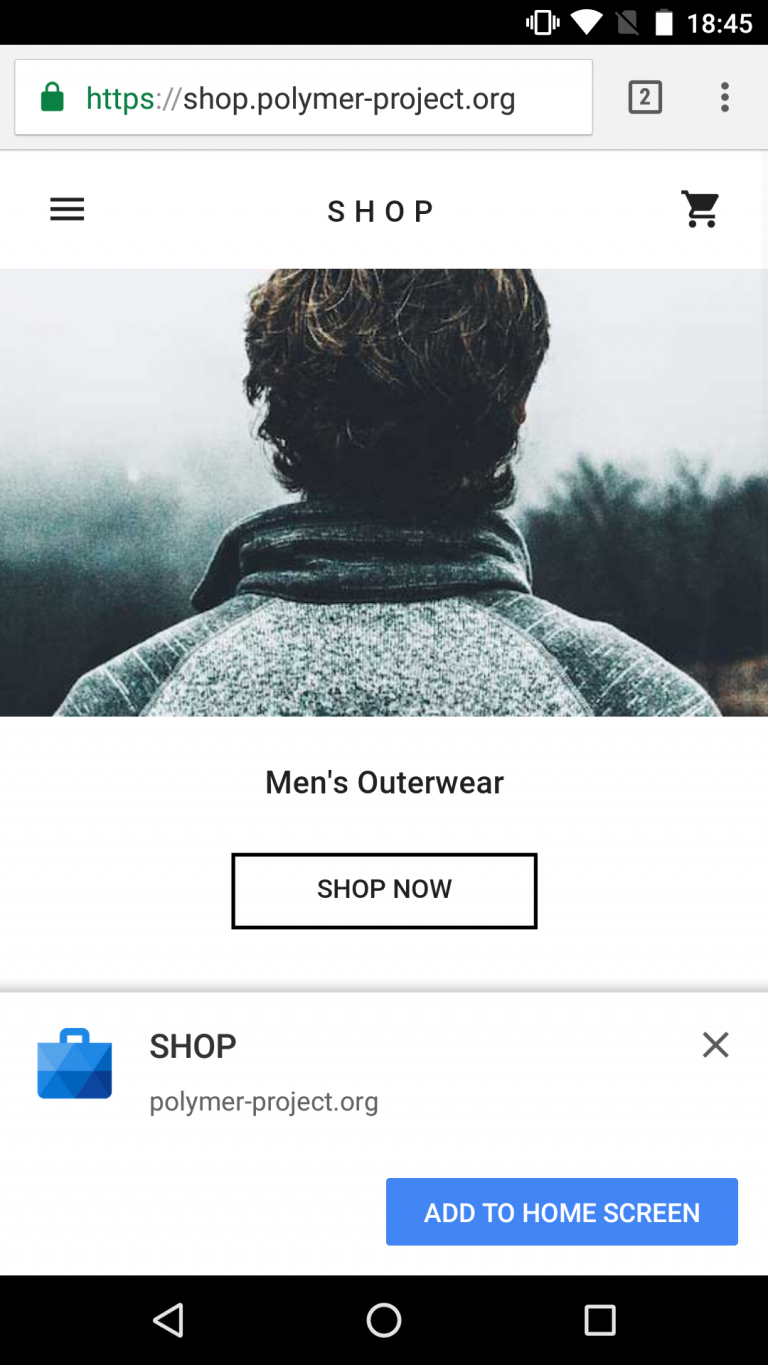
Chrome's Progressive Web App Install prompt on the Polymer Shop demo.
I'd know. In January 2015 I designed the criteria that Chrome uses to trigger "Add to Homescreen" prompts. These prompts are what let users know that a site is a Progressive Web App. Sites that earn a spot on the homescreen report increased long-term engagement with these users.
Questions remain about what criteria browsers should enforce to gate prompting; that conversation is healthy, but this article isn't a contribution to it. Similarly, per-browser criteria are not cataloged. Instead, this article focuses on the strictest common criteria to ensure broad installability as of late 2016. Proprietary and legacy technologies (e.g., AppCache) are also out of scope as they don't contribute to prompting. This article is a time-capsule. The set of things you need to do today to cause your site to be recognized by browsers and bots as an installable Progressive Web App.
In general, installability criteria are tightening. Today's Good-To-Haves may become part of tomorrow's baseline. The opposite is unlikely because at least one major browser has made a strong commitment to tightening up the rules for installability.
Baseline Appyness
A Progressive Web App is functionally defined by the technical properties that allow the browser to detect that the site meets certain criteria and is worthy of being added to the homescreen. These criteria are motivated by user-experience concerns. Apps on the homescreen:
Should load instantly, regardless of network state. This isn't to say that they need to function fully offline, but they must put their own UI on screen without requiring a network round trip.
Should be tied in the user's mind to where they came from. The brand or site behind the app shouldn't be a mystery.
Can run without extra browser chrome (e.g., the URL bar). This is a potentially dangerous permission. To prevent hijacking by captive portals (and worse), apps must be loaded over TLS connections.
These concerns give rise to today's Baseline Criteria. To be a Progressive Web App, a site must:
An icon at least 144x144 large in png format. E.g.: "icons": [ { "src": "/images/icon-144.png", "sizes": "144x144", "type": "image/png" } ]
Browsers do not enforce these requirements uniformly but if a browser does prompt for installation, sites that do these things will be installable today.
Plugged-in readers may note that no browser enforces the requirements about loading quickly on flaky connections or loading while offline. Enforcement is coming shortly; at least to Chrome.
Good-to-Haves
Some criteria are situational or specific to particular form-factors. For example, an immersive game may need to run full-screen and may only want to work in a single orientation. That set of choices is an anti-pattern for a news app. Similarly, not every app needs to send users Push Notifications. This means that the following should be thought of as a score over-and-above the lowest passing grade. In US educational terms, doing well in these criteria will be the difference between a C- and an A-:
From correct viewport specification to tap-target size, it's important that PWAs work well across form factors and screen sizes. Responsive Design can reduce the time and effort required to achieve this.
Near-instant loading.
Progressive Web Apps should be interactive (loaded and free of long-running scripts) in less than 5 seconds on a representative connection on a representative device (see below) before a Service Worker is installed.
Once the Service Worker is active, apps should load (be interactive) in less than a 2 seconds. This should not vary with network state.
Work across devices & browsers.
A well-built site must work for 90+% of all users in its market.
While Progressive Enhancement is ideal, it's possible to meet this requirement with multiple versions, although having multiple domains (e.g. "m.*") is something to avoid if possible.
Fluid animations.
Visual transitions should not stutter or jank.
A+ Progressive Web Apps
A+ apps need to meet the highest experience bar. To hit this bar, A+ Progressive Web Apps (in addition to the above) should:
Be mobile-friendly, not mobile-only.
For most sites Responsive Design is appropriate. Teams that do not build multiple versions of their site should ensure their apps work equally well in desktop, mobile, and all form-factors in between.
Implement high quality UI/UX that makes the experience feel highly interactive.
Users should be able to understand what actions they can take while offline. They should not get "stranded" tapping on links to sections of an app that can't work.
Web Push Notifications and Background Sync can enable timely experiences and thoughtful "outbox" functionality provide a delightful improvement on the status quo.
Great UIs take effort to build and polish, but the results can be incredible both for users and businesses. Frameworks are starting to adapt to these demands, e.g. the PRPL pattern and similar architectures for high-performance app loading, making it easier than ever to deliver amazing experiences on the web that hit all of the PWA high notes.
Getting Ready For Prime Time
That's a lot to think about!
Verifying that your PWA meets some of most of these criteria, specifically the baseline requirements, has required a great deal of manual testing…until recently. Thanks to the new Lighthouse project, it's possible to automate checks for many of these properties. You can even integrate Lighthouse into continuous integration systems to catch regressions.
DevTools is also improving rapidly to help you see the impact of changes. The new Security and Applications tabs allow quick diagnosis of common gotchas at development time.
Building a high-quality Progressive Web App has incredible benefits. A great experience can delight users and improve business outcomes. A bit of up-front planning, on-device testing, and iteration with Lighthouse can make it easier to realise them.
Endnote: Representative Devices
Performance testing is difficult!
A primary issue is the broad diversity in network and device performance. Developers tend to own devices (both desktop and mobile) that are significantly faster than the devices their apps will be experienced on. Many developers I've spoken with have never used chrome://inspect. They are frequently surprised to find their applications to be unacceptably slow on real phones.
To avoid this, it's imperative to be testing on real phones. But which ones? In an ideal world, automated testing of real-world performance would be trivially available in our continuous integration systems. Lighthouse attempts to emulate some aspects of mobile devices to provide actionable insight, but teams who are striving for A+ status need mid-tier devices to verify these results on.
Which ones to buy? The answer is market-dependent. The broader a service's reach, the lower-end the target phone should be. Networks also differ by market. "3G" often means something wildly different in practice in different geographies and even when users may have access to LTE service in theory, changing network conditions frequently put users into slower connections.
In late 2016, the following phones & testing settings strike a decent balance for their markets:
These recommendations attempt to be middle-of-the road in terms of price and capability. If your team is going for the best possible experience, don't be afraid to standardise on cheaper or older devices!