Platform Adjacency Theory
TL;DR: Does it matter if the web platform adds new capabilities? And if it should, which ones? The web is a meta-platform. Like other meta-platforms the web thrives or declines to the extent it can accomplish the lion's share of the things we expect most computers to do. Adjacency to the current set of capabilities provides a disciplined way to think about where to invest next when working to stave off irrelevance. If distribution of runtimes is blocked, competition falters, and adjacent capabilities can go un-addressed. Ecosystem decline, and eventual collapse, follows. Apple and Mozilla posturing about risks from new capabilities is belied by accepted extant native platform risks. For different reasons, they are both working to cast the web in amber. We will all have lost a future worth wanting should they succeed.
Chromium's Project Fugu 🐡 is an open collaboration between Google, Microsoft, Intel, Samsung, and others to safely bring capabilities to the web which native developers have come to expect. Henrik's piece on our work is particularly lucid about the concrete value of new, seemingly-abstract features. Allowing some subset of trusted web apps to access the serial ports (with user/admin consent) isn't academic; it's helping Henrik deliver health care at lower cost. Suz Hinton's talks on WebUSB show the through-line: as the web gets more capable, whole classes of software suddenly benefit from frictionless deployment, increased safety, better privacy, and more meaningful user controls. After all, those are properties that browsers compete on, benefiting users in the process.
We started down this path with Project Fizz in '14. That (mobile-first) work added PWA installability, Push Notifications, Web Bluetooth, WebUSB, and Background Sync. Fugu 🐡 expands our remit to desktop and new classes of apps via powerful APIs — everything from codecs to windowing controls to font access to Serial and HID devices — a list that might seem like a semi-random grab bag. In retrospect, and without context, the features we delivered in Fizz may also appear random.[1] Expansions of the web's power can seem by turns scary, capricious, or a distraction from the real problems developers face.[2]
We've faced our fair share of push-back, often from other browser engines, usually shrouded in privacy rhetoric.[3] So, why do this? Why push through the sorts of snide comments Henrik highlighted? Why risk so much on new features when there's a never-ending list of things that need to be fixed with the existing set?
The answer lies in what I have come to understand as Platform Adjacency Theory.
Our Random Walk #
Folks who claim "the web doesn't need that!" invariably point to successes brought by things that the web already does, as though it is a logically coherent set.
But is it?
Why does it make sense for a browser to speak only HTTP, MIME-encode a fixed set of data types with corresponding (inextensible!) form elements, decode (but not always encode) a subset of popular media formats, and marry that to a constraint-solver for laying out text and drawing boxes?[4] Oh, and it should be imperatively programmed with Lisp-in-C's-clothing.

Recall that browsers arose atop platforms that universally provided a host of services by the late 90's:
- System fonts (to support layout programs, including WYSIWYG editing)
- High-color raster graphics and compositing
- Vector rendering
- Rich multimedia (animations, video, audio)
- Multi-tasking & concurrent programming
- TCP/IP & UDP networking, including local network discovery
- POSIX filesystems & removable media (e.g. floppy/CD/DVD)
- Built-in relational SQL database engines
- Device I/O via serial, USB, and HID
- Printer support
The web wasn't the only meta-platform in this era. Meta-platforms exist to abstract over their hosts, providing a uniform surface API to create portability. Portability reduces single-platform lock-in, often (but not always) buttressed by open standards option-value. Because meta-platforms intermediate, they have the ability to provide ecosystem benefits that are difficult for underlying platforms to replicate, e.g. lower distribution friction, streaming content execution, faster platform updates, and better security. These traits manifest as faster development, iterative deployment, and lower cost of ownership for businesses and developers. To convert these theoretical benefits to real gains, meta-platforms implement runtimes for each underlying OS. Runtimes need wide distribution to make meta-platforms attractive to developers. This matters because it is the corpus of attractive content uniquely available through a meta-platform that convinces users to adopt its runtime, and no platform developer can afford to build enough content to be compelling on their own.
A few meta-platforms achieved wide distribution by the turn of the century, earning a chance at handling tasks previously requiring native Win32 binaries. Shockwave and Flash leaned into scripting, graphics, and multimedia. Distribution in the Windows XP base image ensured Flash was a part of desktop computing for more than a decade afterwards. Huge reach, plus the licensing of On2's video codecs, made Flash the default video delivery mechanism for many years.
Java arrived with a focus on structured programming (including threads), GUI controls, networking, device access, and graphics. Distribution was competitive, with multiple implementations (some tied to browsers) sometimes complicating the platform for developers.[5] As with other meta-platforms of the time, early browser plug-ins provided avenues for runtime and content distribution.[6] Java found some client-side niches, particularly in enterprise. Absent compelling content and attentive security and performance focus, it soon retreated to the server.[7]
Since the end of the first browser wars, most of the world's consumer computers retained baseline 90's features (CD drives and printers excepted) while adding:
- Cellular, Wifi, Bluetooth, and NFC radios
- A lab's worth of sensors, including:
- Cameras (both still and video)
- Microphones
- Proximity
- Temperature
- Accelerometer
- Ambient light
- Barometer
- Location (GPS)
- Compass (magnetometer)
- Orientation (gyroscope)
- Touch digitisers
- Biometric (e.g. fingerprint, IR mapping)
- GPU-accelerated graphics, compute, and media encode/decode
- Vector instructions (SSE, AVX, Neon)[8]
Some legacy devices lack some of these features, however, all commodity operating systems support them and the plurality of devices sold have them. The set of things "most computers do" started larger than what the early web supported (particularly without plug-ins) and continues to accelerate away.
The Overlapping Competitions #
Every computing platform is locked in overlapping competitions. The first is for developer time and attention. The set of successful applications not built to your platform is a bug to the mind of every competent platform strategist (malware excepted). It is a problem for OSes when developers do not use their APIs directly, but instead reach for portability layers atop the native surface. Developers deliver content. Compelling content and services draw users. If the weight of these experiences is compelling enough, it can even convince potential users to acquire your device or runtime to get access. The resulting install base of a platform and it's capabilities are an asset in convincing the next developer to build for a platform.[9] This plays out in a loop over time, either adding or shedding momentum from a platform. Winning the second competition (install base growth) in each iteration makes it ever easier to draw developer attention — assuming the platform remains competitively capable.
Teams make roughly exclusive choices about platforms for each project. Maximizing user-experience quality and reach from the smallest possible investment is how developers justify outsized rewards for easily learned skills. Meta-platforms enter this calculus with a deficit to maximum capability and performance but (hopefully) gains to reach. When an application's essential needs can be handled effectively while providing a competitive enough user experience, meta-platforms can win the business. In situations where key capabilities in a domain are missing from a meta-platform, applications simply won't appear there. This results in higher (per-OS) development, acquisition, and maintenance costs for the ecosystem (often centralizing benefits to fewer, capital-rich players) and leading to other deadweight losses.[10]
Consider this straw-person conceptual framing:
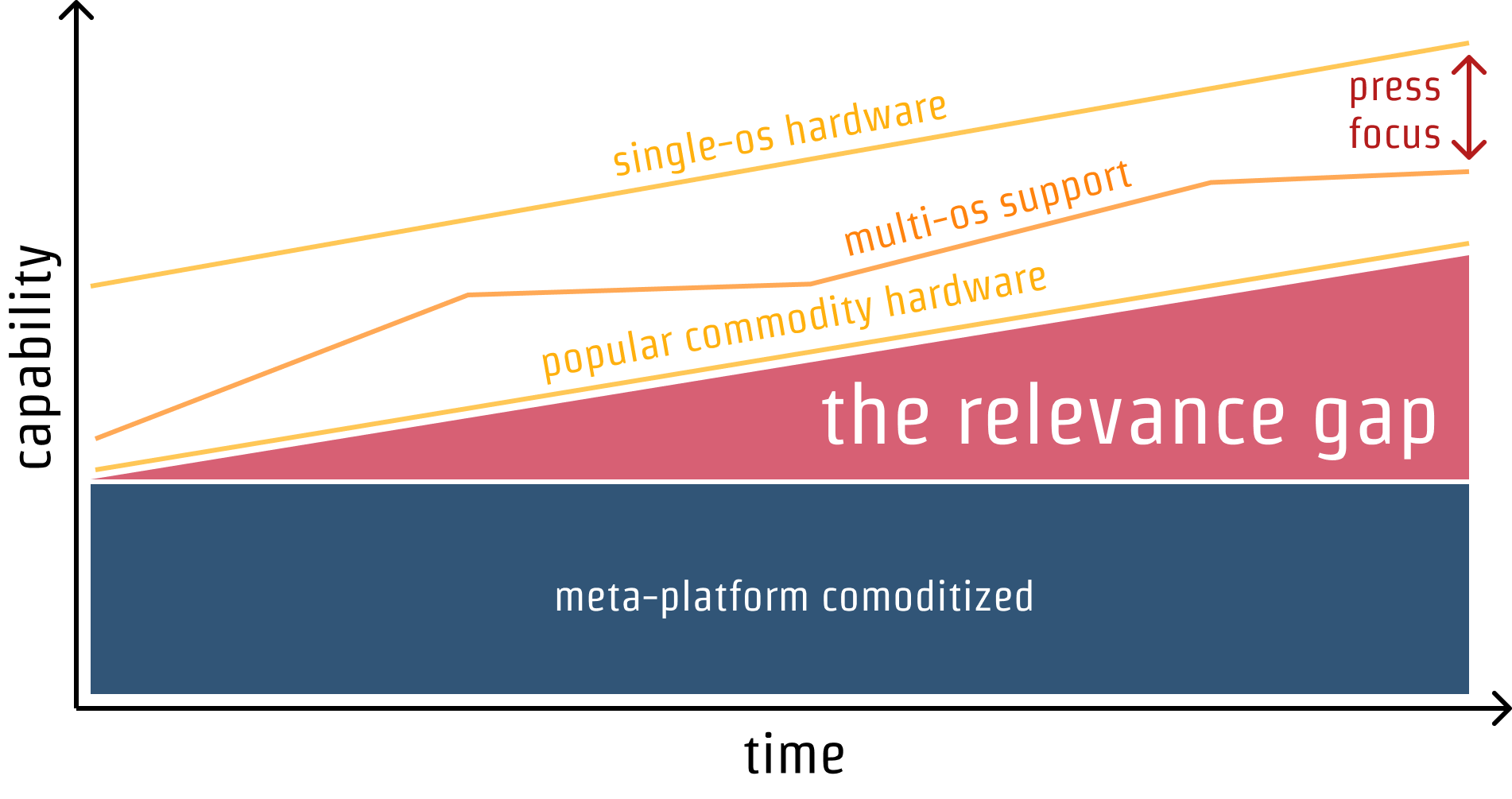
Our theoretical meta-platform starts at the left (Time 0) with a relatively complete set of features versus what most computers can do, but substantially less than the leading edge, and perhaps trailing what all commodity operating systems provide by some amount. There will be some apps that can't be attempted, but most can. Developers are making decisions under uncertainty at every point, and the longer a platform lives and the more successful it is, the less risk to developers in betting on it. Assuming wide distribution for our meta-platform, it's a good bet for most developers across the majority of the graph's width.
In each quantum of time, hardware and OS vendors press ahead, adding features. Some "exotic" features become commonplace, widely supported across the deployed fleet of devices. As OS and hardware deployed base integrate these components, the set of what most computers can do is expanded. This is often determined by hardware integration and device replacement rates. The fates of these advances occupy the majority of tech press (and, sadly, developer) attention thanks to marketing from vendors looking to differentiate at the high-end (where margins both exist and require justification).[11]
Toward the right-hand side of our chart, the meta-platform that once looked like a good bet is suddenly legacy technology. By failing to keep up with what most computers can do, or even increase at a constant rate such that the height of the relevance gap remains constant, developers making a choice might want to re-use knowledge they've gained from earlier cycles betting on the meta-platform, but will likely need to route around the suddenly-stagnant legacy system.
But why should it feel sudden when, in reality, the trend lines are nearly constant over time?
Consider the re-development cycles of products and services. If teams re-evaluate their stack choices only at the start, middle, and end of the chart our meta-platform will appear to go from excitingly competent, to mildly concerning (but still more than capable), to a career and product risk. Each of these moments is experienced stochastically in our model, with the final moment presenting a previously un-hedged risk. Developer FOMO can be self-fulfilling; exoduses from platforms aren't so much the result of analysis so much as collective and personal ego defenestration. The Twitter bios of any 10 randomly picked programmers will confirm the identitarian aspects of platforms and their communities. Breaks with these identities are sharp and painful, leading to tribal flight. Assuming the capability gap doesn't close, developers moving their attention seals the fate of our straw-person meta-platform.
It doesn't have to be this way, though. There's no technical reason why, with continued investment, meta-platforms can't integrate new features. As the set expands, use cases that were previously the exclusive purview of native (single-OS) apps can transition to the meta-platform, gaining whatever benefits come with its model.
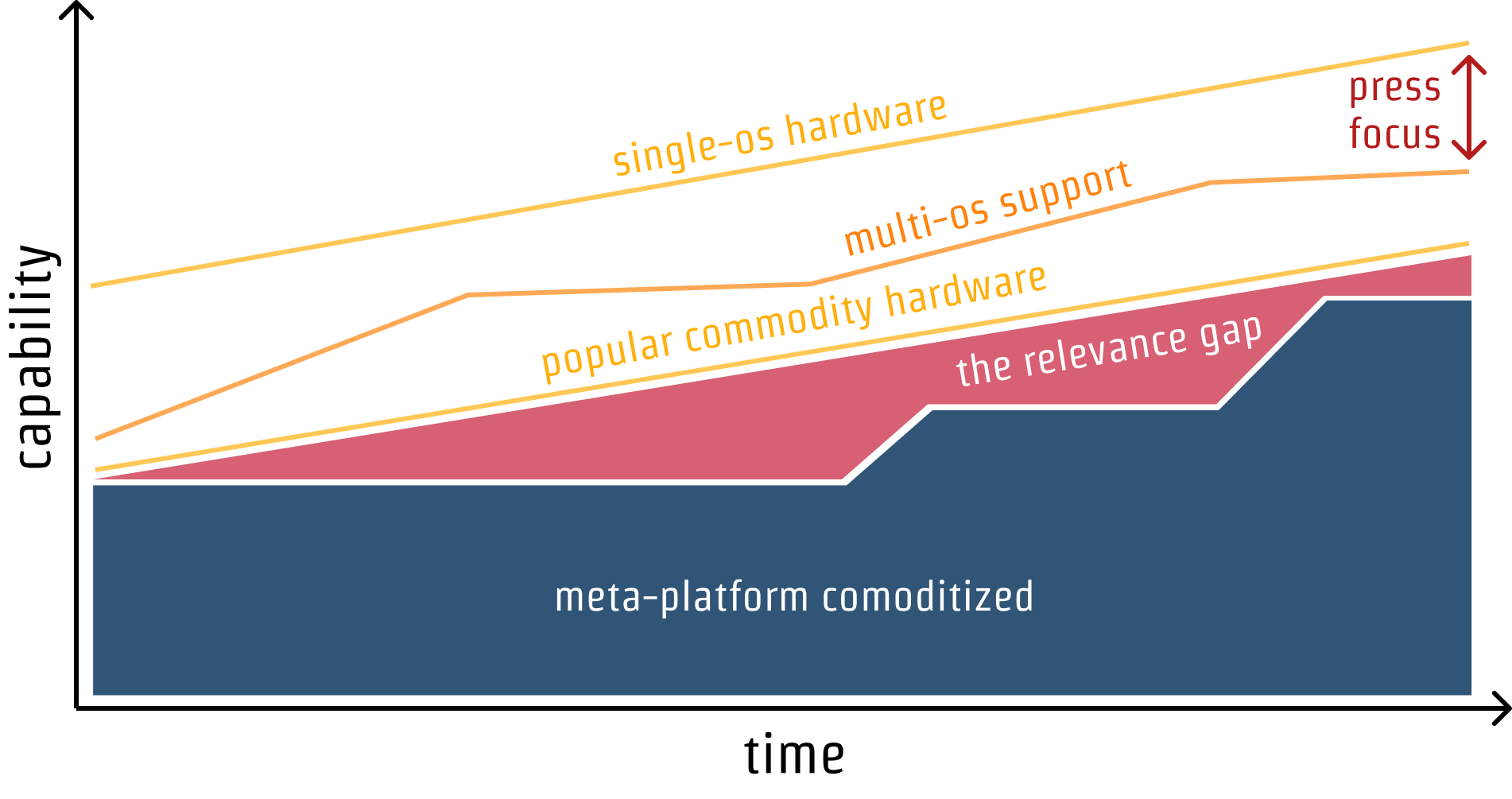
If our theoretical team encountered the platform evolution in this chart at the moments we discussed earlier, it would still be a good bet at the right-hand side of the chart, even including sizeable stagnant periods.
Katamari Capability #
The web's benefits of frictionless deployment, universal access, streaming execution, collaboration, security, and user choice are model advantages for both content and services. Together, they make software better.
Software moves to the web (when not prevented by poor browsers and/or unconscionable policy) because it's a better version of computing:
kwokchain.com/2020/06/19/why-figma-wins/
It has been really surprising to me how few frontend folks are investing deeply in sync & collaboration tech.

But not every application can make the leap. Consider the set of features the circa-2000 web could handle:
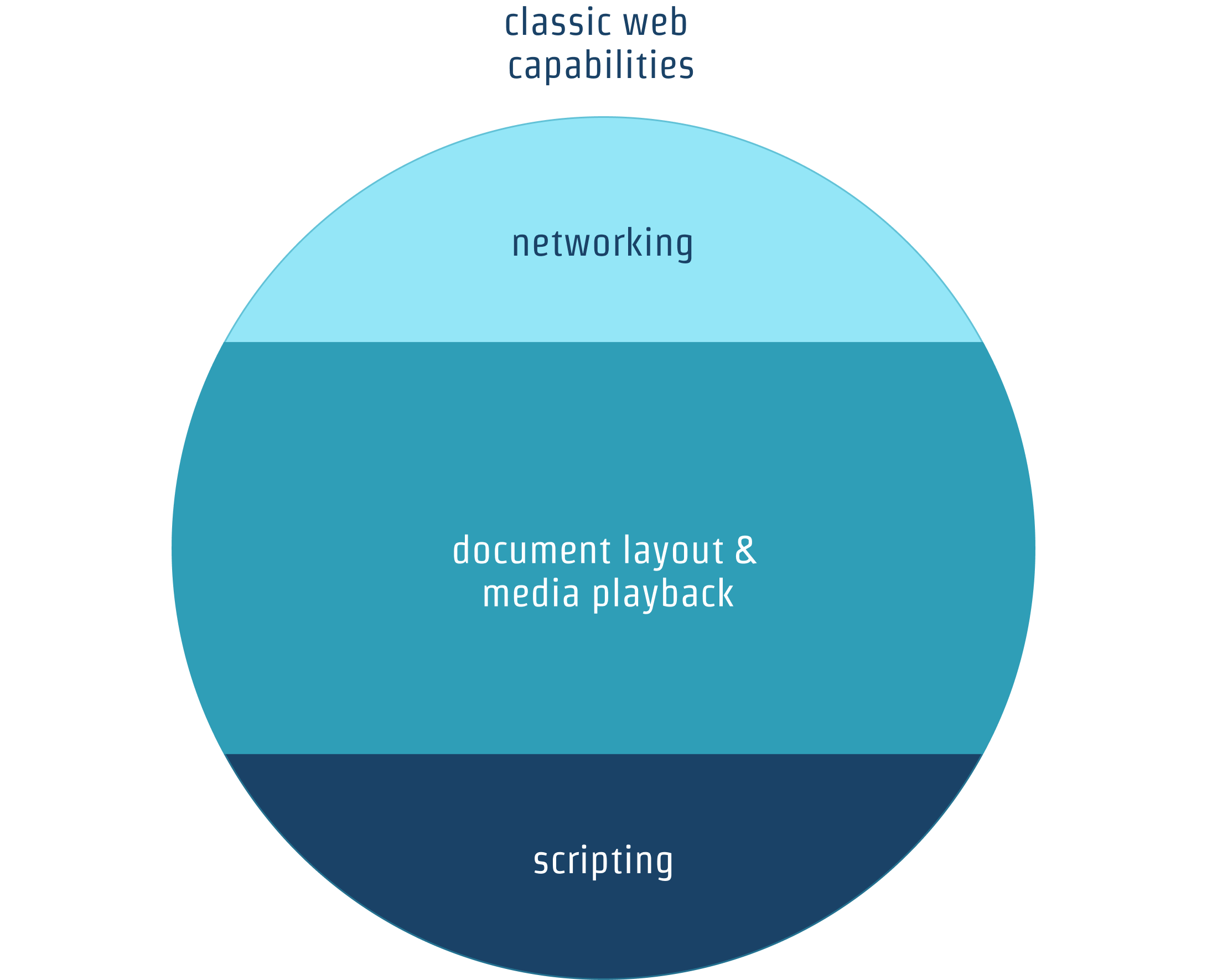
Starting from a text-only document format in 1990, the web added features at a furious pace in the first decade, but not in a principled way. Whatever the motivations of early browser hackers, some use-cases were very near to the original needs of academic information sharing, news delivery among them:[12]

The system was capable enough by 1995 to support an Ajax-y email, but the experiences weren't a tight fit with user expectations of the time.[13]

The Jobs To Be Done of an email client are:
- Rendering text and images
- Previewing and downloading attachments
- Email authoring and spellcheck
- Folder management
- OS integration (as a
mailto:link handler) - POP, IMAP, SMTP, and MAPI server communication
- Offline consumption and authoring[14]
Only the last two proved challenging once Ajax was possible across browsers, sparking desktop email's inexorable move to the web. Some things never got ironed out. Web-based clients still can't talk IMAP or POP directly, and the look-and-feel of web clients isn't 1:1 with any OS. Nice-to-have features didn't impact adoption much.[15] The web's model advantages more than made up for cosmetic deficiencies when security, cost, and ease-of-access were factored in. Being just capable enough unlocks massive value through model shifts.
Other use-cases weren't addressable with early aughts tech. WebEx and Skype and Tandberg and many other video conferencing solutions emerged on native and didn't cross over to the web until relatively recently. They needed what early browsers could do, but much, much more as well. Rendering text is important (think login screens), but there's no product without low-latency, adaptive codecs, networking, and camera/microphone access.

The surface area of needs swamped the capabilities of the early web.
Between the end of the first browser wars and today, we added adjacent capabilities to unlock core use-cases in this area. Fast-forward to modern browsers, and Zoom, WebEx, Google Meet, Jitsi, and even Skype work well (and most safely) on the web.

We still haven't covered every possible feature of the native versions of these tools, but enough is there to enable a massive shift way from desktop-native apps; a still-unfinished transition that I expect to last at least another half decade:

This is the core loop at the heart of platform adjacency theory. The next set of important use-cases for a platform to tackle often isn't simply an improvement on what it can already do.[16]
Growing a platform's success requires unlocking use-cases not already serviced. That mean finding needs that combine things your platform is already good at with a small number of missing capabilities, as big-bang investments into new areas rarely create the sort of feedback loop and partner engagement that can help you make the dozens of critical course corrections along the way.
This is playing out now with video conferencing, screen-sharing, and streamed gaming (e.g. Stadia and GeForce NOW) which combine various forms of input capture (mouse, keyboard, gamepad, and HID) with codec, networking, and window management improvements to displace heavily-used native apps.
Productivity apps have a similar texture, missing access to fonts, files, and high-end compute...but not for long. Google Earth, SketchUp, Figma, Photopea, and many more are starting to explore what's possible in anticipation of even richer features.
For platform makers, adjacency is both a roadmap and a caution flag. Instead of directly going after AAA games, we should instead find segments of gaming that can be mostly unlocked by what we've already got plus a small number of critical additions that unlock the key experience features. Same with IDEs and developer tools. Same with utilities. Instead of adding direct support for hardware features available on less than 1% of deployed devices and supported by a single OS, we should focus on features already within the set of things most computers can do that enjoy wide OS support.
The time provided to learn and course-correct is a secondary benefit to adjacency-based incremental addition. New APIs always have issues, and ironing out the kinks, removing performance cliffs, and understanding the next set of adjacent needs happens best when talking with bought-in developers who are succeeding (if trailblazing) in your newly-opened space.
The Committee To Cast The Web In Amber #
There is a contingent of browser vendors today who do not wish to expand the web platform to cover adjacent use-cases or meaningfully close the relevance gap that the shift to mobile has opened.
Apple is "deciding not to implement" a long list of features for reasons that boil down to some variant of "it's hard and we don't want to try". This is, of course, bad for users and developers because it creates a larger market for substantially less secure, substantially less mediated, and less privacy-preserving native software.[17][18][19]
Going back to our stagnant meta-platform straw-person, what result should we expect?
At any short-run moment, there won't be much change. Remember, developers don't feel trends as a smooth set of tiny increments. The "lumpy" nature of platform choices makes short-run gap growth less of a concern, particularly when there have historically been fast catch-up phases between stagnant periods.
Further, the status quo does not change quickly, and the web is one of a handful of generational computing platforms. But there have been others that have fallen into relative disuse, and once the smell of death hangs over a platform and its use declines below a fuzzy threshold, precipitous ecosystem collapse follows, reducing the platform's carrying capacity going forward. This doom-loop effect precludes even medium-term recovery to growth. Importantly, collapse isn't the same thing as extinction; mainframes hardly went away, but the set of use-cases primarily addressed by Fortan and COBOL programmers has been fixed in a narrow band for a long, long time. Once the ecosystem collapses, return to growth is prevented by market perception as much as technical capacity. Nobody buys a car they can't imagine themselves driving.[20]
It takes a lot to push a vibrant ecosystem to collapse. Technical ecosystems are complex systems, with layers of resilience built-in. Unfortunately, much has already been done to speed the web's irrelevance.
Tools like Cordova and Electron are manifestations of a relevance gap so large, so painful that developers are willing to abandon one (or more) core benefits of web deployment in return for (presumed) necessary discovery and capability access parity.
Claims that adjacent APIs are rarely used are (generously) confused.[21] Low use of an individual API says nothing about the size of the gap it contributes to or the cumulative impact of un-addressable use-cases growing without bound. Such claims are also wildly out of step with the demonstrated needs of developers and the breadth of capabilities available to native app developers.
Developers building on meta-platforms are in competition with each other, but also services built directly to underlying operating system APIs. Apple is claiming (simultaneously) that native app developers should continue to enjoy a nearly unbounded advantages about commodity capabilities and that meaningful engine competition on iOS isn't worth wanting.[22] Never mind that a competition can demonstrate how common capabilities can be safely provided by browsers willing to risk their reputations and market position to pioneer new protections.[23]
Impressively, these arguments are made with a straight face against a backdrop of more than a decade to come up with workable alternatives.[24]
What developers should reasonably expect from viable meta-platforms is not instant access to every single feature of high-margin, low-volume devices. However, steady integration of things most computers can do into the safer, standards-based, open, universally available meta-platforms should be the norm. Something is fundamentally broken in a market when a participant prevents meta-platforms from closing the commodity capability gap. iOS is prevalent enough in discrete, wealthy geographies like the US and the UK for Apple's anti-browser-choice policies to distort the market worldwide. This distortion is more, not less, impactful for its prevalance among the wealthy. Folks with money for thousand dollar phones shape technology decision making and purchasing. If the web can't be relevant to them, it's a dead letter.
Web developers do not (and should not) expect zero-friction availability from every web page to the entire suite of sensors attached to every computer.[25] It wouldn't serve anyone, and it's not what we're providing through Project Fugu. Instead, we are doing the work to explore the fuzzy and complex space of user consent, usage indicators, revokability, and recall — the exact space that operating systems are iterating on too, but with worse results (on average). We seek at every moment to build upon whatever baseline level of safety that operating systems provide and do better along these axes, the way the web historically has with other sensitive capabilities.
Competition is key to unlocking new, creative approaches to this set of problems and the next. Without competition, and paired to structural under-investment by both Apple and Mozilla, we know what a growing relevance gap will do; it's just a question of time.
Every organism cast in amber is, after all, deceased.
Thanks to Josh Bell, Jonathan Bingham, Henrik Joreteg, Frances Berriman, Jeffery Yasskin, and Sam Dutton for their thoughtful feedback on drafts of this post. Remaining errors persist because I produce them at a rate their combined powers cannot surmount.
Both Fizz and Fugu heavily prioritised the needs of engaged partners who communicated clearly what would unblock them in moving their best experiences to the web. Our seemingly random walk has been anything but. ↩︎
"The real problems" are invariably defined in terms of incremental improvements to better serve developers already on the platform. In a situation where your platform supports most of computing, that's not wrong.
The web, however, is not in that situation, thanks to mobile, which is now most of computing. Focusing exclusively or primarily on current developers when you're the underdog is, therefore, a critical strategic error. Unlocking what's needed to bring computing to the web on mobile is the only way to stave off irrelevance. ↩︎
Apple and Mozilla's privacy argument requires specialist knowledge to assess, which might be why they picked it.
Why isn't it a privacy risk to add all these new scary sounding features to the web?
First, know that no browser is currently in a position to make meaningful anti-fingerprinting claims of any sort. Apple's early attempts backfired, ironically creating an unclearble "supercookie". Side channels are hard to defeat. To prevent effective fingerprinting we must ensure that no more than 31 or 32 bits of potential identifying information are available. Above that threshold, the jig is up.
The use of IP networks, and the lack of pervasive onion-routing (think Tor) uses up substantially all of this space for most users today. Variance added by screen resolutions, assistive technologies (including system font sizes), and availability of hardware acceleration for many operations (video decoding, graphics operations, cryptography, etc.) ensures that nearly all web users are above the threshold even with the entire set of currently marketed privacy protections in place.
What is left, then, is a set of wicked problems: we must work to prevent expansion of ambiently available additional information while trying to remediate existing issues, while at the same time acknowledging that solutions to the current set fingerprinting surface-area issues are going to be applicable to new features too. Existing geolocation, WebGL, and directory upload APIs have substantially the same problems as presented by the new crop of features.
There is, of course a simple solution: a browser that doesn't do very much.
Nobody is making or marketing that browser today (tho they easily could), and the counterfactual in which most web use moves to it is also a world where computing moves off the web and onto fundamentally less secure and less privacy-preserving platforms. Assuming we don't want that, we must find solutions to privacy that can be incrementally adopted. That's the thinking behind Chrome's work to (for the first time) write down a real threat model for general-purpose browsing and the Privacy Sandbox project. These aren't the only potential approaches, of course. Many alternatives are possible for exposing new capabilities in constrained ways to make fingerprinting less effective and/or more transparent.
For instance, browsers could chose to expose new device APIs only to installed PWAs with separate storage, or could chose to create UIs with increasing intensity of push-back as more sites request overlapping access, or even outright cap the number of sites that a user can "bless" with a permission. This is not an exhaustive list of potential fixes. The problem is hard, pre-existing, and has many possible solutions.
Vendors that ship the existing set of potentially problematic features while refusing to acknowledge the symmetry of the new and old capabilities — and their solutions — are not squaring with developers or users. We hope to do better through Privacy Budgets, Trust Tokens, and First-Party Sets., but as with all claims about general-purpose browser fingerprinting, we're in the early stages.
Whatever solutions emerge will absolutely constrain Fugu APIs as well as legacy capabilities. It is non sequitur to claim privacy or fingerprinting as the basis to avoid adding features. Making the claim, however, indicates either worrisome confusion about how to effectively protect user privacy or is a telling admission of problematic under-investment. ↩︎
But never LaTeX quality layout (regardless of how fast CPUs get). ↩︎
It didn't have to be that way. Sun's justified suspicions of MSFT cemented Java 1.1 in the ecosystem much longer than was natural. A sad story with a bad ending. ↩︎
By the time Microsoft tried the same tactics to introduce Silverlight — including paying for the rights to exclusive distribution for the '08 Summer Olympic Games — users and developers had become wary of plug-ins. A tarnished developer reputation from browser-war shenanigans surely didn't help. ↩︎
Java was later plucked from server obscurity by Android's Dalvik VM which made client-side friendly trade-offs that Sun had persistently resisted; memory is precious and start-up time really does matter. ↩︎
Neural net acceleration will soon be on the list. ↩︎
Conversely, a perceived lack of users or capabilities is a risk to developers considering supporting a platform. ↩︎
Building things separately for each OS supported has linear effects on technical performance, but creates non-linear impairments to organisational efficiency.
Experiences might be faster because they're custom-written, but not often enough to justify the adjacent costs. From coordinating design, to iteration speed, to launch coordination, to merging metrics feedback, the slowdowns incurred at the business level can let competitors into your OODA loop unless you're product's key benefit is maximum performance on the specific silicon in question. Meta-platforms flourish (when allowed by platform players) because they meaningfully reduce the amount of time bad decisions go uncorrected. ↩︎
One way to conceive of meta-platforms and open standards is that, like Open Source, they help to reduce the pricing power of incumbents regarding commodity features that just happen to be wrapped up in proprietary APIs.
Dropping the price of long-ago developed features distributed at zero marginal cost is a form of pricing pressure. This works against rent extraction and forces competitors to plow economic windfalls into new development to justify continued high prices. To the extent it is the economy's job to accelerate the rate at which technology and scientific breakthroughs become widely-shared benefits in society, this is intensely desirable. ↩︎
While not strictly necessary for advertising, things really took off when
<iframe>anddocument.write()made ad placement dynamic. I submit, however, that news would likely have moved to the web in a fully-static, forms-and-cookies-and-images world too. ↩︎Reliable offline email has been a constant struggle, starting with Gears, continuing with AppCache, and culminating in Service Workers. Only took a decade! ↩︎
Arguments from consistency with the OS tend to overlook the end-state: rendering and form inputs could become consistent by getting full-fidelity with native....or they could achieve internal consistency across sites. It's really a question of which platform users spent most of their time in. If that platform is the browser, OS fidelity drops in importance for users. ↩︎
If iteration can unlock outsized value, you'll know it by investigating the performance of the best-constructed apps on your platform. My experience from a decade of platform work, though, suggests that efficiency gains are most often returned to developer comfort rather than user experience. What can be built is often the same at the start and end of an optimisation journey unless the gains are at least an order of magnitude. You're usually better off tackling latency with aggressive performance budgeting. ↩︎
You can take a browser vendor at face value on claimed benefits to not addressing the relevance gap the minute they ship a browser that does not allow native binaries to be downloaded or app stores linked to from the web. Until then, this represents, at best, confusion about the mission and, at worst, distraction from user-hostile inaction. ↩︎
"deciding not to implement" is language that chiefly serves to deflect critique of world's first trillion-dollar company for structural under-investment in their browser engine combined with policies that explicitly prevent meaningful browser choice on iOS. This keeps others from picking up the pieces the way Firefox did on Windows in the early '00s.
The game becomes clear when zooming out to include missing or years-late capabilities that aren't covered by the too-small "privacy" fig-leaf, including (but very much not limited to):
- anything based on Worklets (Audio Worklet, CSS Custom Paint, Animation Worklet)
- Scroll-Linked Animations, WebGL 2
- Shared Array Buffers
- Standards-based Push Notifications
<dialog>- Broadcast Channel
- WebXR
- Credential Management
- The CSS Typed Object Model
- Web Packaging
...among others. ↩︎
Mozilla's position is, at best, confused. At worst, it is misdirection. For opaque reasons, the Mozilla Foundation is declining to invest sufficiently in engine development (pdf) whilst simultaneously failing to challenge Apple's anti-competition stance on mobile engine choice.
This is a 180-degree turnaround from the energy and mission that powered the original Mozilla Manifesto and Firefox project. Declining to compete on features while giving air-cover to a competitor that won't let you stand on even footing goes against everything the web community was led to believe Mozilla stands for.
The web and the world need a vibrant Mozilla, one that is pushing against unfairness and expanding what's possible on open platforms. A Mozilla that won't answer the call of it's manifesto is not succeeding, even on its own terms. ↩︎
The market mismatch between COBOL skills and needs is a textbook refutation of the efficient market hypothesis.
Demographics being what they are, we should have a small over-supply of COBOL programmers in 2020, rather than a crash effort to find willing pensioners or train-up new grads. Tribal identity about software systems often leaves good money on the table. ↩︎
Less generously, claims of low individual API use are deployed as chaff to convince non-participants to the debate that one "side" is engaged in special-pleading and that there's no cause for legitimate concern.
Were that the case, however, hardware vendors would begin to withdraw these sensors and capabilities to save on the almighty Bill of Materials (BOM) that directly determines OEMs profitability. If an OEM is making this case whilst shipping these sensors and supporting them with OS-level APIs and controls, caveat emptor. ↩︎
Mozilla, Google, Opera, and many others have failed to make a public issue over the lack of effective browser choice in iOS. I'm disappointed by the entire browser community on this front, but hope that perhaps by banding together — and with developer support — we might coordinate a message to users that helps inform them understand how they're being denied access to the best version of the web on iOS. This is worth fighting for, including taking hits in user perception in the short run. ↩︎
One particularly disingenuous argument brought about by Apple's defenders is that they couldn't have made ITP (the unintentional supercookie API) happen if meaningful browser choice had been allowed on iOS.
This is a surprising claim, given that it was successfully introduced on Safari for MacOS.
More perniciously, it also presumes that Apple is incapable of making an iOS browser that users will actually want. I have more faith in the quality of Apple engineering than this, having seen them best larger teams over and over in open competition. Why do Apple's nominal defenders have such little confidence? ↩︎
If anything, we're excruciatingly late to unlock these capabilities in Project Fugu. One would have expected a device vendor with total control of hardware, OS, and browser to have either come to the conclusion that no third party should have access to them, or that there are conditions (which can be re-created on the web by inspection) under which it's safe.
There isn't a middle ground, only an indefensible status quo. ↩︎
Arguments about why the web can't have these things in a-priori limited, heavily mediated ways...but that they're ok in native apps...must account for the ways that native developers — including the SDKs they pervasively invite into their binaries — count on unfettered access. It's transparently false that native platform prevent fingerprinting through these mechanism; indeed, they go further and directly provide stable, rarely-cycled, on-by-default device IDs to all callers.
Those IDs might help provide semantic transparency and improved user control in a world where OS vendors clamp down on direct fingerprinting or begin to audit SDK behaviour.
But that's not happening.
Curious. ↩︎

.svg){kind=link}