A Management Maturity Model for Performance
Since 2015 I have been lucky to collaborate with more than a hundred teams building PWAs and consult on some of the world's largest sites. Engineers and managers on these teams universally want to deliver great experiences and have many questions about how to approach common challenges. Thankfully, much of what once needed hand-debugging by browser engineers has become automated and self-serve thanks to those collaborations.
Despite advances in browser tooling, automated evaluation, lab tools, guidance, and runtimes, teams I've worked with consistently struggle to deliver minimally acceptable performance with today's popular frameworks. This is not a technical problem per se — it's a management issue, and one that teams can conquer with the right frame of mind and support.
What is Performance? #
It may seem a silly question, but what is performance, exactly?
This is a complex topic, but to borrow from a recent post, web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Performance isn't a binary and there are no silver bullets.
Only teams that master their systems can make intentional trade-offs. Organisations that serve their tools will tread water no matter how advanced their technology, while groups that understand and intentionally manage their systems can succeed on any stack.[1]
Value Propositions #
The value of performance is deeply understood within a specific community and in teams that have achieved high maturity. But outside those contexts it can be challenging to communicate. One helpful lens is to view the difference between good and bad performance as a gap between expectations and reality.
For executives that value:
- Revenue
Performance is a significant revenue contributor. To the extent that a product performs poorly, a fraction of revenue will be lost and the narrower the funnel becomes for all types of conversions.[2] - Engagement
Poor performance has a well-documented relationship to reduced engagement. The space between good and bad performance is the opportunity for a competitor's product to fill the same opening. An under-appreciated aspect of this equation is variance. When a product often performs well but sometimes is slow to respond, users lose trust and use that service less. Consistent performance matters just as much as low average latency. - Design
Poor performance is a gap between the responsiveness of Figma mockups and lived brand reality. Product that perform well are closer to the approved design spec. Many brands build their reputations on fanatical attention to detail about the products they sell and the physical environments they're sold in. A laggy digital experience is out of alignment with these brand values. - Accessibility
Performance is the foundation of access. Users experiencing slow services may be unable to access them in the first place, mooting other work poured into improving a11y. Reduced network and device capacity correlate with other access challenges. a11y that isn't founded on consistently excellent performance can easily veer into performative, rather than effective, territory.
Performance is rarely the single determinant of product success, but it can be the margin of victory. Improving latency and reducing variance allows teams to test other product hypotheses with less noise. A senior product leader recently framed a big performance win as creating space that allows us to be fallible in other areas.
Protecting the Commons #
Like accessibility, security, UI coherence, privacy, and testability, performance is an aggregate result. Any single component of a system can regress latency or create variance, which means that like other cross-cutting product properties, performance must be managed as a commons. The approaches that work over time are horizontal, culturally-based, and require continual investment to sustain.
Teams I've consulted with are too often wrenched between celebration over launching "the big rewrite" and the morning-after realisation that the new stack is tanking business metrics.
Now saddled with the excesses of npm, webpack, React, and a thousand promises of "great performance" that were never critically evaluated, it's easy for managers to lose hope. These organisations sometimes spiral into recrimination and mistrust. Where hopes once flourished, the horrors of a Bundle Buddy readout looms. Who owns this code? Why is it there? How did it get away from the team so quickly?
Many "big rewrite" projects begin with the promise of better performance. Prototypes "seem fast", but nobody's actually benchmarking them on low-end hardware. Things go fine for a while, but when sibling teams are brought in to integrate late in the process, attention to the cumulative experience may suffer. Before anyone knows it, the whole thing is as slow as molasses, but "there's no going back"... and so the lemon launches with predictably sour results.
In the midst of these crises, thoughtful organisations begin to develop a performance management discipline. This, in turn, helps to create a culture grounded in high expectations. Healthy performance cultures bake the scientific method into their processes and approaches; they understand that modern systems are incredibly complex and that nobody knows everything — and so we learn together and investigate the unknown to develop an actionable understanding.
Products that maintain a healthy performance culture elevate management of latency, variance, and other performance attributes to OKRs because they understand how those factors affect the business.
Levels of Performance Management Maturity #
Performance management isn't widely understood to be part of what it means to operate a high-functioning team. This is a communcation challenge with upper management, but also a potential differentiator or even a strategic advantage. Teams that develop these advantages progress through a hierarchy of management practice phases. In drafting this post, I was pointed to similar work developed independently by others[3]; that experienced consultants have observed similar trends helps give me confidence in this assessment:
Level 0: Bliss #

Level 0 teams do not know they have a problem. They may be passively collecting some data (e.g., through one of the dozens of analytics tools they've inevitably integrated over the years), but nobody looks at it. It isn't anyone's job description to do so.
Folks at this level of awareness might also simply assume that "it's the web, of course it's slow" and reach for native apps as a panacea (they aren't). The site "works" on their laptops and phones. What's the problem?
Management Attributes #
Managers in Level 0 teams are unaware that performance can be a serious product problem; they instead assume the technology they acquired on the back of big promises will be fine. This blindspot usually extends up to the C-suite. They do not have latency priorities and they uncritically accept assertions that a tool or architecture is "performant" or "blazing fast". They lack the technical depth to validate assertions, and move from one framework to another without enunciating which outcomes are good and which are unacceptable. Faith-based product management, if you will.
Level 0 PMs fail to build processes or cultivate trusted advisors to assess the performance impacts of decisions. These organisations often greenlight rewrites because we can hire easily for X, and we aren't on it yet
. These are vapid narratives, but Level 0 managers don't have the situational awareness, experience, or confidence to push back appropriately.
These organisations may perform incidental data collection (from business analytics tools, e.g.) but are inconsistently reviewing performance metrics or considering them when formulating KPIs and OKRs.
Level 1: Fire Fighting #

At Level 1, managers will have been made aware that the performance of the service is unacceptable.[4]
Service quality has degraded so much that even fellow travelers in the tech privilege bubble[4:1] have noticed. Folks with powerful laptops, new iPhones, and low-latency networks are noticing, which is a very bad sign. When an executive enquires about why something is slow, a response is required.
This is the start of a painful remediation journey that can lead to heightened performance management maturity. But first, the fire must be extinguished.
Level 1 managers will not have a strong theory about what's amiss, and an investigation will commence. This inevitably uncovers a wealth of potential metrics and data points to worry about; a few of those will be selected and tracked throughout the remediation process. But were those the right ones? Will tracking them from now on keep things from going bad? The first firefight instills gnawing uncertainty about what it even means to "be fast". On teams without good leadership or a bias towards scientific inquiry, it can be easy for Level 1 investigations to get preoccupied with one factor while ignoring others. This sort of anchoring effect can be overcome by pulling in external talent, but this is often counter-intuitive and sometimes even threatening to green teams.
Competent managers will begin to look for more general "industry standard" baseline metrics to report against their data. The industry's default metrics are moving to a better place, but Level 1 managers are unequipped to understand them deeply. Teams at Level 1 (and 2) may blindly chase metrics because they have neither a strong, shared model of their users, nor an understanding of their own systems that would allow them to focus more tightly on what matters to the eventual user experience. They aren't thinking about the marginal user yet, so even when they do make progress on directionally aligned metrics, nasty surprises can reoccur.
Low levels of performance management maturity are synonymous with low mastery of systems and an undeveloped understanding of user needs. This leaves teams unable to quickly track down culprits when good scores on select metrics fail to consistently deliver great experiences.
Management Attributes #
Level 1 teams are in transition, and managers of those teams are in the most fraught part of their journey. Some begin an unproductive blame game, accusing tech leads of incompetence, or worse. Wise PMs will perceive performance remediation work as akin to a service outage and apply the principles of observability culture, including "blameless postmortems".
It's never just one thing that's amiss on a site that prompts Level 1 awareness. Effective managers can use the collective learning process of remediation to improve a team's understanding of its systems. Discoveries will be made about the patterns and practices that lead to slowness. Sharing and celebrating these discoveries is a crucial positive attribute.
Strong Level 1 managers will begin to create dashboards and request reports about factors that have previously caused problems in the product. Level 1 teams tend not to staff or plan for continual attention to these details, and the systems often become untrustworthy.
Teams can get stuck at Level 1, treating each turn through a Development ➡️ Remediation ➡️ Celebration loop as "the last time". This is pernicious for several reasons. Upper management will celebrate the first doused fire but will begin to ask questions about the fourth and fifth blazes. Are their services just remarkably flammable? Is there something wrong with their team? Losing an organisation's confidence is a poor recipe for maximising personal or group potential.
Next, firefighting harms teams, and doubly so when management is unwilling to adopt incident response framing. Besides potential acrimony, each incident drains the team's ability to deliver solutions. Noticeably bad performance is an expression of an existing feature working below spec, and remediation is inherently in conflict with new feature development. Level 1 incidents are de facto roadmap delays.
Lastly, teams stuck in a Level 1 loop risk losing top talent. Many managers imagine this is fine because they're optimising for something else, e.g. the legibility of their stack to boot camp grads. A lack of respect for the ways that institutional knowledge accelerates development is all too common.
It's difficult for managers who do not perceive the opportunities that lie beyond firefighting to comprehend how much stress they're placing on teams through constant remediation. Fluctuating between Levels 1 and 0 ensures a team never achieves consistent velocity, and top performers hate failing to deliver.
The extent to which managers care about this — and other aspects of the commons, such as a11y and security — is a reasonable proxy for their leadership skills. Line managers can prevent regression back to Level 0 by bolstering learning and inquiry within their key personnel, including junior developers who show a flair for performance investigation.
Level 2: Global Baselines & Metrics #
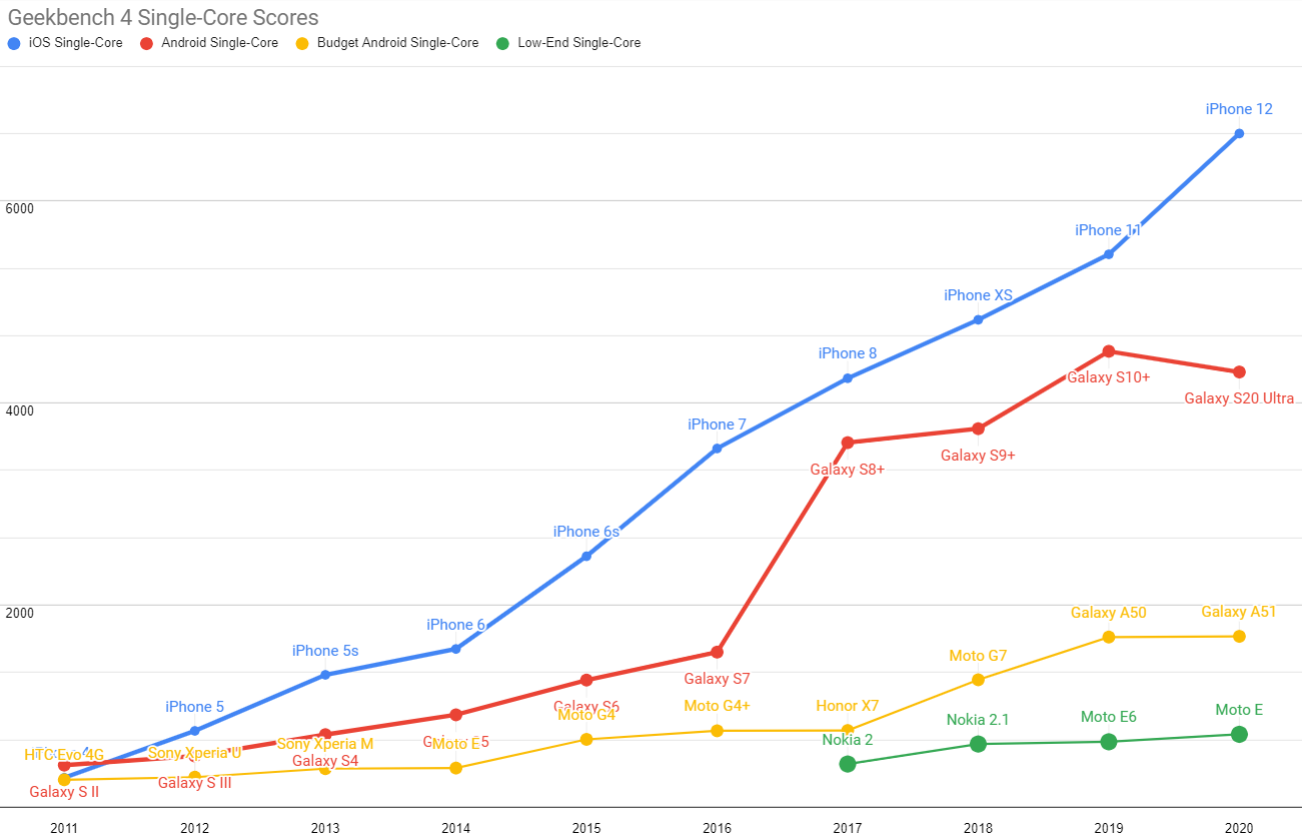
Thoughtful managers become uncomfortable as repeated Level 1 incidents cut into schedules, hurt morale, and create questions about system architecture. They sense their previous beliefs about what's "reasonable" need to be re-calibrated... but against what baseline?
It's challenging for teams climbing the maturity ladder to sift through the many available browser and tool-vendor data points to understand which ones to measure and manage. Selected metrics are what influence future investments, and identifying the right ones allows teams to avoid firefighting and prevent blindspots.

Teams looking to grow past Level 1 develop (or uncover they already had) Real User Monitoring ("RUM data") infrastructure in previous cycles. They will begin to report to management against these aggregates.
Against the need for quicker feedback and a fog of metrics, managers who achieve Level 2 maturity look for objective, industry-standard reference points that correlate with business success. Thankfully, the web performance community has been busy developing increasingly representative and trustworthy measurements. Still, Level 2 teams will not yet have learned to live with the dissatisfaction that lab measurements cannot always predict a system's field behavior. Part of mastery is accepting that the system is complex and must be investigated, rather than fully modeled. Teams at Level 2 are just beginning to learn this lesson.
Strong Level 2 managers acknowledge that they don't know what they don't know. They calibrate their progress against studies published by peers and respected firms doing work in this area. These data points reflect a global baseline that may (or may not) be appropriate for the product in question, but they're significantly better than nothing.
Management Attributes #
Managers who bring teams to Level 2 spread lessons from remediation incidents, create a sense of shared ownership over performance, and try to describe performance work in terms of business value. They work with their tech leads and business partners to adopt industry-standard metrics and set expectations based on them.
Level 2 teams buy or build services that help them turn incidental data collection into continual reporting against those standard metrics. These reports tend to focus on averages and may not be sliced to focus on specific segments (e.g., mobile vs. desktop) and geographic attributes. Level 2 (and 3) teams may begin drowning in data, with too many data points being collected and sliced. Without careful shepherding to uncover the most meaningful metrics to the business, this can engender boredom and frustration, leading to reduced focus on important RUM data sources.
Strong Level 2 managers will become unsatisfied with how global rules of thumb and metrics fail to map directly into their product's experience and may begin to look for better, more situated data that describe more of the user journeys they care about. The canniest Level 2 managers worry that their teams lack confidence that their work won't regress these metrics.
Teams that achieve Level 2 competence can regress to Level 1 under product pressure (removing space to watch and manage metrics), team turnover, or assertions that "the new architecture" is somehow "too different" to measure.
Level 3: P75+, Site-specific Baselines & Metrics #

The unease of strong Level 2 management regarding metric appropriateness can lead to Level 3 awareness and exploration. At this stage, managers and TLs become convinced that the global numbers they're watching "aren't the full picture" — and they're right!
At Level 3, teams begin to document important user journeys within their products and track the influence of performance across the full conversion funnel. This leads to introducing metrics that aren't industry-standard, but are more sensitive and better represent business outcomes. The considerable cost to develop and validate this understanding seems like a drop in the bucket compared to flying blind, so Level 3 teams do it, in part, to eliminate the discomfort of being unable to confidently answer management questions.
Substantially enlightened managers who reach Level 3 will have become accustomed to percentile thinking. This often comes from their journey to understand the metrics they've adopted at Levels 1 and 2. The idea that the median isn't the most important number to track will cause a shift in the internal team dialogue. Questions like, "Was that the P50 number?" and "What does it look like at P75 and P90?" will become part of most metrics review meetings (which are now A Thing (™).
Percentiles and histograms become the only way to talk about RUM data in teams that reach Level 3. Most charts have three lines — P75, P90, and P95 — with the median, P50, thrown in as a vanity metric to help make things legible to other parts of the organisation that have yet to begin thinking in distributions.
Treating data as a distribution fundamentally enables comparison and experimentation because it creates a language for describing non-binary shifts. Moving traffic from one histogram bucket to another becomes a measure of success, and teams at Level 3 begin to understand their distributions are nonparametric, and they adopt more appropriate comparisons in response.
Management Attributes #
Level 3 managers and their teams are becoming scientists. For the first time, they will be able to communicate with confidence about the impact of performance work. They stop referring to "averages", understand that medians (P50) can tell a different story than the mean, and become hungry to explore the differences in system behavior at P50 and outlying parts of the distribution.
Significant effort is applied to the development and maintenance of custom metrics and tools. Products that do not report RUM data in more sliceable ways (e.g., by percentile, geography, device type, etc.) are discarded for those that better support an investigation.
Teams achieving this level of discipline about performance begin to eliminate variance from their lab data by running tests in "less noisy" environments than somewhere like a developer's laptop, a shared server, or a VM with underlying system variance. Low noise is important because these teams understand that as long as there's contamination in the environment, it is impossible to trust the results. Disaster is just around the corner when teams can't trust tests designed to keep the system from veering into a bad state.
Level 3 teams also begin to introduce a critical asset to their work: integration of RUM metrics reporting with their experimentation frameworks. This creates attribution for changes and allows teams to experiment with more confidence. Modern systems are incredibly complex, and integrating this experimentation into the team's workflow only intensifies as groups get ever-more sophisticated moving forward.
Teams can regress from Level 3 because the management structures that support consistent performance are nascent. Lingering questions about the quality of custom metrics can derail or stall progress, and some teams can get myopic regarding the value of RUM vs. lab data (advanced teams always collect both and try to cross-correlate, but this isn't yet clear to many folks who are new to Level 3). Viewing metrics with tunnel vision and an unwillingness to mark metrics to market are classic failure modes.
Level 4: Variance Control & Regression Prevention #

Strong Level 3 managers will realise that many performance events (both better and worse than average) occur along a user journey. This can be disorienting! Everything one thought they knew about how "it's going" is invalidated all over again. The P75 latency for interaction (in an evenly distributed population) isn't the continuous experience of a single user; it's every fourth tap!
Suddenly, the idea of managing averages looks naive. Medians have no explanatory power and don't even describe the average session! Driving down the median might help folks who experience slow interactions, but how can the team have any confidence about that without constant management of the tail latency?
This new understanding of the impact that variance has on user experiences is both revelatory and terrifying. The good news is that the tools that have been developed to this point can serve to improve even further.
Level 4 teams also begin to focus on how small, individually innocuous changes add up to a slow bleed that can degrade the experience over time. Teams that have achieved this sort of understanding are mature enough to forecast a treadmill of remediation in their future and recognise it as a failure mode. And failure modes are avoidable with management processes and tools, rather than heroism or blinding moments of insight.
Management Attributes #
Teams that achieve Level 4 maturity almost universally build performance ship gates. These are automated tests that watch the performance of PRs through a commit queue, and block changes that tank the performance of important user flows. This depends on the team having developed metrics that are known to correlate well with user and business success.
This implies all of the maturity of the previous levels because it requires a situated understanding of which user flows and scenarios are worth automating. These tests are expensive to run, so they must be chosen well. This also requires an investment in infrastructure and continuous monitoring. Making performance more observable, and creating a management infrastructure that avoids reactive remediation is the hallmark of a manager who has matured to Level 4.
Many teams on the journey from Level 3 to 4 will have built simpler versions of these sorts of gates (bundle size checks, e.g.). These systems may allow for small continuous increases in costs. Over time, though, these unsophisticated gates become a bad proxy for performance. Managers at Level 4 learn from these experiences and build or buy systems to watch trends over time. This monitoring ought to include data from both the lab and the field to guard against "metric drift". These more sophisticated monitoring systems also need to be taught to alert on cumulative, month-over-month and quarter-over-quarter changes.
Level 4 maturity teams also deputise tech leads and release managers to flag regressions along these lines, and reward them for raising slow-bleed regressions before they become crises. This responsibility shift, backed up by long-run investments and tools, is one of the first stable, team-level changes that can work against cultural regression. For the first time, the team is considering performance on longer time scales. This also begins to create organisational demand for latency budgeting and slowness to be attributed to product contributions.
Teams that achieve Level 4 maturity are cautious acquirers of technology. They manage on an intentional, self-actualised level and value an ability to see through the fog of tech fads. They do bake-offs and test systems before committing to them. They ask hard questions about how any proposed "silver bullets" will solve the problems that they have. They are charting a course based on better information because they are cognizant that it is both valuable and potentially available.
Level 4 teams begin to explicitly staff a "performance team", or a group of experts whose job it is to run investigations and drive infrastructure to better inform inquiry. This often happens out of an ad-hoc virtual team that forms in earlier stages but is now formalised and has long-term staffing.
Teams can quickly regress from Level 4 maturity through turnover. Losing product leaders that build to Level 4 maturity can set groups back multiple maturity levels in short order, and losing engineering leaders who have learned to value these properties can do the same. Teams are also capable of losing this level of discipline and maturity by hiring or promoting the wrong people. Level 4 maturity is cultural and cultures need to be defended and reinforced to maintain even the status quo.
Level 5: Strategic Performance #

Teams that fully institutionalise performance management come to understand it as a strategic asset.
These teams build management structures and technical foundations that grow their performance lead and prevent cultural regressions. This includes internal training, external advocacy and writing[5], and the staffing of research work to explore the frontier of improved performance opportunities.
Strategic performance is a way of working that fully embeds the idea that "faster is better", but only when it serves user needs. Level 5 maturity managers and teams will gravitate to better-performing options that may require more work to operate. They have learned that fast is not free, but it has cumulative value.
These teams also internally evangelise the cause of performance. Sibling teams may not be at the same place, so they educate about the need to treat performance as a commons. Everyone benefits when the commons is healthy, and all areas of the organisation suffer when it regresses.
Level 5 teams institute "latency budgets" for fractional feature rollouts. They have structures (such as managers or engineering leadership councils) that can approve requests for non-latency-neutral changes that may have positive business value. When business leaders demand the ability to ram slow features into the product, these leaders are empowered to say no
.
Lastly, Level 5 teams are focused on the complete user journey. Teams in this space can make trades intelligently, moving around code and time within a system they have mastered to ensure the best possible outcomes in essential flows.
Management Attributes #
Level 3+ team behaviours are increasingly illegible to less-advanced engineers and organisations. At Level 5, serious training and guardrails are required to integrate new talent. Most hires will not yet share the cultural norms that a strategically performant organisation uses to deliver experiences with consistent quality.[6]
Strategy is what you do differently from the competition, and Level 5 teams understand their way of working is a larger advantage than any single optimisation. They routinely benchmark against their competition on important flows and can understand when a competitor has taken the initiative to catch up (it rarely happens through a single commit or launch). These teams can respond at a time of their choosing because their lead will have compounded. They are fully out of firefighting mode.
Level 5 teams do not emerge without business support. They earn space to adopt these approaches because the product has been successful (thanks in part to work at previous levels). Level 5 culture can only be defended from a position of strength. Managers in this space are operating for the long term, and performance is understood to be foundational to every new feature or improvement.
Teams at Level 5 degrade more slowly than at previous levels, but it does happen. Sometimes, Level 5 teams are poor communicators about their value and their values, and when sibling teams are rebuffed, political pressure can grow to undermine leaders. More commonly, enough key people leave a Level 5 team for reasons unrelated to performance management, like when the hard-won institutional understanding of what it takes to excel is lost. Sometimes, simply failing to reward continual improvement can drive folks out. Level 5 managers need to be on guard regarding their culture and their value to the organisation as much as the system's health.
Uneven Steps, Regression, & False Starts #
It's possible for strong managers and tech leads to institute Level 1 discipline by fiat. Level 2 is perhaps possible on a top-down basis in a small or experienced team. Beyond that, though, maturity is a growth process. Progression beyond global baseline metrics requires local product and market understanding. TLs and PMs need to become curious about what is and isn't instrumented, begin collecting data, then start the directed investigations necessary to uncover what the system is really doing in the wild. From there, tools and processes need to be built to recreate those tough cases on the lab bench in a repeatable way, and care must be taken to continually re-validate those key user journeys against the evolving product reality.
Advanced performance managers build groups that operate on mutual trust to explore the unknown and then explain it out to the rest of the organisation. This means that advancement through performance maturity isn't about tools.
Managers who get to Level 4 are rare, but the number who imagine they are could fill stadiums because they adopted the technologies that high-functioning leaders encourage. But without the trust, funding to enquire and explore, and an increasingly fleshed-out understanding of users at the margins, adopting a new monitoring tool is a hollow expenditure. Nothing is more depressing than managerial cosplay.
It's also common for teams to take several steps forward under duress and regress when heroics stop working, key talent burns out, and the managerial focus moves on. These aren't fatal moments, but managers need to be on the lookout to understand if they support continual improvement. Without a plan for an upward trajectory, product owners are putting teams on a loop of remediation and inevitable burnout... and that will lead to regression.
The Role of Senior Management #
Line engineers want to do a good job. Nobody goes to work to tank the product, lose revenue, or create problems for others down the line. And engineers are trained to value performance and quality. The engineering mindset is de facto optimising. What separates Level 0 firefighting teams from those that have achieved self-actualised Level 5 execution is not engineering will; it's context, space, and support.
Senior management sending mixed signals about the value of performance is the fastest way to degrade a team's ability to execute. The second-fastest is to use blame and recrimination. Slowness has causes, but the solution isn't to remove the folks that made mistakes, but rather to build structures that support iteration so they can learn. Impatience and blame are not assets or substitutes for support to put performance consistently on par with other concerns.
Teams that reach top-level performance have management support at the highest level. Those managers assume engineers want to do a good job but have the wrong incentives and constraints, and it isn't the line engineer's job to define success — it's the job of management.
Questions for Senior Managers #
Senior managers looking to help their teams climb the performance management maturity hill can begin by asking themselves a few questions:
-
Do we understand how better performance would improve our business?
- Is there a shared understanding in the leadership team that slowness costs money/conversions/engagement/customer-success?
- Has that relationship been documented in our vertical or service?
- Do we know what "strategic performance" can do for the business?
-
What constraints have we given the team?
- Do they have a device-class or network condition target?
- Can engineers rely on those targets to negotiate with other parts of the organisation (e.g., sales, marketing, etc.)?
-
Have we developed a management fluency wth histograms and distributions over time?
- Do we write OKRs for performance?
- Are they phrased in terms of marginal device and network targets, as well as distributions?
-
What support do we give teams that want to improve performance?
- Do folks believe they can appeal directly to you if they feel the system's performance will be compromised by other decisions?
- Can folks (including PMs, designers, and SREs — not just engineers) get promoted for making the site faster?
- Can middle managers appeal to performance as a way to push back on feature requests?
- Are there systems in place for attributing slowness to changes over time?
- Can teams win kudos for consistent, incremental performance improvement?
- Can a feature be blocked because it might regress performance?
- Can teams easily acquire or build tools to track performance?
-
What support do we give mid-level managers who push back on shiny tech in favour of better performance?
- Have we institutionalised critial questions for adopting new technologies?
- Are aspects of the product commons (e.g., uptime, security, privacy, a11y, performance) managed in a coherent way?
- Do managers get as much headcount and funding to make steady progress as they would from proposing rewrites?
-
Have we planned to staff a performance infrastructure team?
- It's the job of every team to monitor and respond to performance challenges, but will there be a group that can help wrangle the data to enable everyone to do that?
- Can any group in the organisation serve as a resource for other teams that are trying to get started in their latency and variance learning journeys?
The answers to these questions help organisations calibrate how much space they have created to scientifically interrogate their systems. Computers are complex, and as every enterprise becomes a "tech company", becoming intentional about these aspects is as critical as building DevOps and Observability to avoid downtime.
It's always cheaper in the long run to build understanding than it is to fight fires, and successful management can create space to unlock their team's capacity.
"o11y, But Make it Performance" #
Mature technology organisations may already have and value a discipline to manage performance: "Site Reliability Engineering" (SRE), aka "DevOps", aka "Observability". These folks manage and operate complex systems and work to reduce failures, which looks a lot like the problems of early performance maturity teams.
These domains are linked: performance is just another aspect of system mastery, and the tools one builds to manage approaches like experimental, flagged rollouts need performance to be accounted for as a significant aspect of the success of a production spike.
Senior managers who want to build performance capacity can push on this analogy. Performance is like every other cross-cutting concern; important, otherwise un-owned, and a chance to differentiate. Managers have a critical role to forge solidarity between engineers, SREs, and other product functions to get the best out of their systems and teams.
Everyone wants to do a great job; it's the manager's role to define what that means.
It takes a village to keep my writing out of the ditch, so my deepest thanks go to Annie Sullivan, Jamund Ferguson, Andy Tuba, Barry Pollard, Bruce Lawson, Tanner Hodges, Joe Liccini, Amiya Gupta, Dan Shappir, Cheney Tsai, and Tim Kadlec for their invaluable comments and corrections on drafts of this post.
High-functioning teams can succeed with any stack, but they will choose not to. Good craftsmen don't blame their tools, nor do they carry deficient implementations.
Per Kellan Elliot-McCrea's classic "Questions for new technology", this means that high-functioning teams will not be on the shiniest stack. Teams choices that are highly correlated with hyped solutions are a warning sign, not an asset. And while "outdated" systems are unattractive, they also don't say much at all about the quality of the product or the team.
Reading this wrong is a sure tell of immature engineers and managers, whatever their title. ↩︎
An early confounding factor for teams trying to remediate performance issues is that user intent matters a great deal, and thus the value of performance will differ based on context. Users who have invested a lot of context with a service will be less likely to bounce based on bad performance than those who are "just browsing". For example, a user that has gotten to the end of a checkout flow or are using a government-mandated system may feel they have no choice. This isn't a brand or service success case (failing to create access is always a failure), but when teams experience different amounts of elasticity in demand vs. performance, it's always worth trying to understand the user's context and intent.
Users that "succeed" but have a bad time aren't assets for a brand or service, they're likely to be ambasassadors for any other way to accomplish their tasks. That's not great, long-term, for a team or for their users. ↩︎
Some prior art was brought to my attention by people who reviewed earlier drafts of this post; notably this 2021 post by the Splunk team and the following tweet by the NCC Group from 2016 (as well as a related PowerPoint presentation):
Where are you on the #webperf maturity model? ow.ly/miAi3020A9G #perfmatters
It's comforting that we have all independently formulated roughly similar framing. People in the performance community are continually learning from each other, and if you don't take my formulation, I hope you'll consider theirs. ↩︎
Something particularly problematic about modern web development is the way it has reduced solidarity between developers, managers, and users. These folks now fundamentally experience the same sites differently, thanks to the shocking over-application of client-side JavaScript to every conceivable problem.
This creates structural illegibility of budding performance crises in new, uncomfortably exciting ways.
In the desktop era, developers and upper management would experience sites through a relatively small range of screen sizes and connection conditions. JavaScript was applied in the breach when HTML and CSS couldn't meet a need.[7] Techniques like Progressive Enhancement ensured that the contribution of CPU performance to the distribution of experiences was relatively small. When content is predominantly HTML, CSS, and images, browsers are able to accelerate processing across many cores and benefit from the ability to incrementally present the results.
By contrast, JavaScript-delivered UI strips the browser of its ability to meaningfully reorder and slice up work so that it prioritises responsiveness and smooth animations. JavaScript is the
fuck it, we'll do it live
way to construct UI, and stresses the relative performance of a single core more than competing approaches. Because JavaScript is, byte for byte, the most expensive thing you can ask a browser to process, this stacks the difficulty involved in doing a good job on performance. JavaScript-driven UI is inherently working with a smaller margin for error, and that means today's de facto approach of using JavaScript for roughly everything leaves teams with much less headroom.Add this change in default architecture to the widening gap between the high end (where all developers and managers live) and the median user. It's easy to understand how perfectly mistimed the JavaScript community's ascendence has been. Not since the promise of client-side Java has the hype cycle around technology adoption been more out of step with average usability.
Why has it gone this badly?
In part because of the privilege bubble. When content mainly was markup, performance problems were experienced more evenly. The speed of a client device isn't the limiting site speed factor in an HTML-first world. When database speed or server capacity is the biggest variable, issues affect managers and executives at the same rate they impact end users.
When the speed of a device dominates, wealth correlates heavily with performance. This is why server issues reliably get fixed, but JavaScript bloat has continued unabated for a decade. Rich users haven't borne the brunt of these architectural shifts, allowing bad choices to fly under the radar much longer which, in turn, increase the likelihood of expensive remediation incidents.
Ambush by JavaScript is a bad time, and when managers and execs only live in the privilege bubble, it's users and teams who suffer most. ↩︎ ↩︎
Managers may fear that by telling everyone about how strategic and important performance has become to them, that their competitiors will wise up and begin to out-execute on the same dimension.
This almost never happens, and the risks are low. Why? Because, as this post exhaustively details, the problems that prevent the competition from achieving high-functioning performance are not strictly technical. They cannot — and more importantly, will not — adopt tools and techniques you evangelise because it is highly unlikely that they are at a maturity level that would allow them to benefit. In many cases, adding another tool to the list for a Level 1-3 team to consider can even slow down and confound them.
Strategic performance is hard to beat because it is hard to construct at a social level. ↩︎
Some hires or transfers into Level 5 teams will not easily take to shared performance values and training.
Managers should anticipate pushback from these quarters and learn to re-assert the shared cultural norms that are critical to success.
There's precious little space in a Level 5 team for résumé-oriented development because a focus on the user has evacuated the intellectual room that hot air once filled. Thankfully, this can mostly be avoided through education, support, and clear promotion criteria that align to the organisation's evolved way of working.
Nearly everyone can be taught, and great managers will be on the lookout to find folks who need more support. ↩︎
Your narrator built JavaScript frameworks in the desktop era; it was a lonely time compared to the clogged market for JavaScript tooling today. The complexity of what we were developing for was higher than nearly every app I see today; think GIS systems, full PIM (e.g., email, calendar, contacts, etc.) apps, complex rich text editing, business apps dealing with hundreds of megabytes worth of normalised data in infinite grids, and BI visualisations.
When the current crop of JavaScript bros tells you they need increased complexity
because business expectations are higher now
, know that they are absolutely full of it. The mark has barely moved in most experiences. The complexity of apps is not much different, but the assumed complexity of solutions is. That experiences haven't improved for most users is a shocking indictment of the prevailing culture. ↩︎
